4 Lists and Iteration using R and {purrr}
vectors, lists, for-loops, purrr
4.1 Introduction
4.1.1 Learning Outcomes
- Manipulate Vectors and Lists using Base R syntax.
- Apply techniques of iteration using
- For-Loops in Base R
map*()functions in the tidyverse {purrr} package
4.1.2 References:
- R for Data Science 2nd Edition Wickham et al. (2023)
- Chapters 3 and 4 in Advanced R Wickham (2023)
- Purrr Overview Wickham and Henry (2023)
4.1.2.1 Other References
4.2 Review of Vectors
- We’ll use just a few tidyverse functions.
4.2.1 R has Two Kinds of Vectors: Atomic Vectors and Lists
Atomic vectors are sequences of elements of the same data type and class.
Lists are data structures where the elements do Not have to be the same class.
- Sometimes called recursive vectors because lists can contain other lists!
Vectors have two main attributes: Length and data Type.
4.2.2 R has Six Data Types
The six data types are:
1. logical,
2. integer,
3. double,
4. character,
5. complex, and
6. raw(byte-level data).factor, anddateclasses are special encodings of data types integer and double.- Integer and double vectors are collectively known as numeric vectors.
Missing Vectors return NULL, like missing or empty values in a vector can return NA.
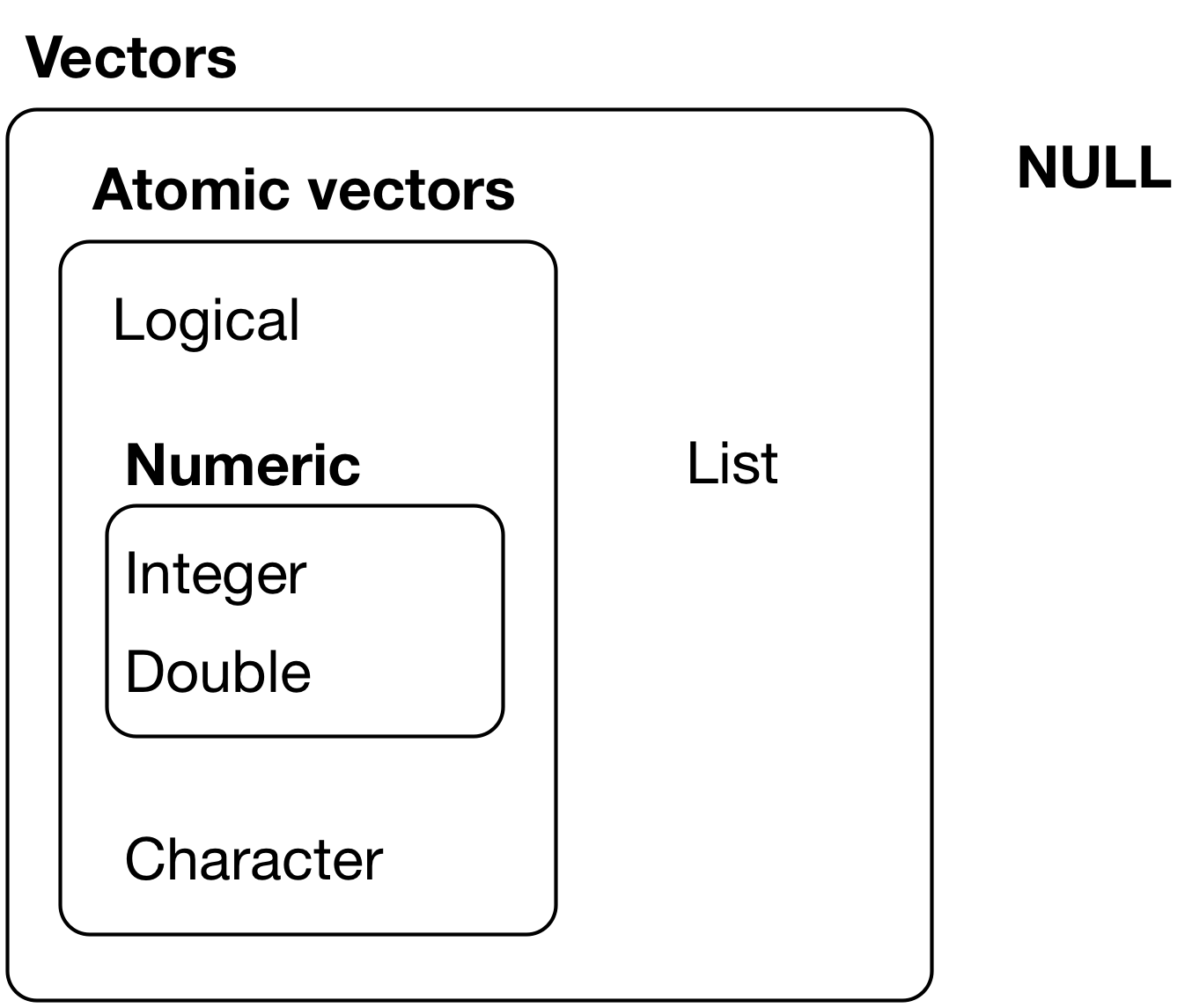 Wickham et al. (2023)
Wickham et al. (2023)
4.2.3 Creating Vectors
Use c() to create a vector from the argument elements.
- use
length()to see the length of a vector. - Use
typeof()to see the type of vector. - Use
is_*()to check the type of vector (from packagepurrr).- e.g.,
is_numeric(),is_logical,is.character, …. - Base R has similar functions
is.*().
- e.g.,
4.2.3.1 Examples
Double:
[1] 3[1] "double"[1] TRUEInteger: use L to tell R to treat (store) a number as an integer:
Character:
[1] 3[1] "character"[1] TRUELogical:
Factor: Factors are actually integers with extra attributes.
[1] A B B
Levels: A B[1] "integer"[1] TRUE[1] "factor"[1] "A" "B"[1] 1 2 2Dates: Dates are actually doubles with extra attributes.
- Dates are the number of days since January 1, 1970, with negative values for earlier dates.
- The POSIXct class stores date/time values as the number of seconds since January 1, 1970.
4.2.4 Working with Elements in a Vector
Each element of a vector can have a name.
See and set/change element names with the names() function.
Subset with brackets [...].
- Brackets are an extract or replace operator (see help for
extract()). - The index object
...can be numeric, logical, character or empty. - Putting a logical vector inside the brackets returns (extracts) the elements from the outer vector where the corresponding value in the inner logical vector is
TRUE.
[1] "like" "dogs"[1] "I" "dogs"Replacement
Extract with negative values to drop elements.
Extract a named vector with the name(s) of the desired element(s) as a character vector.
Two brackets [[...]] only extracts a single element and drops the name.
- The
[[...]]operator performs the[...]operation twice. - Reduces an atomic vector to a named element and then extracts the element out of the named element.
- Useful in working with lists (later on).
4.2.4.1 Exercise
- Create the following vector:
Extract Yoshi and Peach from the above vector using:
- Integer subsetting.
- Negative integer subsetting.
- Logical subsetting.
- Name subsetting.
- In the vector above, replace Yoshi’s number with
19L.
4.2.5 Recycling
You are used to doing vectorized operations.
When operating on a vector with a scalar or two vectors of different lengths, R does what is called “recycling”.
- Internally, R is reusing or “recycling” elements of the scalar or shorter vector to complete the operations. So the above example is treated the same as:
You can choose to recycle non-scalars, i.e., vectors of different lengths, but it’s almost never a good idea as R may not behave how you think it will.
- It makes your code less robust to changes in the data structure over time, e.g., if someone added additional observations to the data:
4.3 Lists
4.3.1 Creating Lists
Lists are vectors whose elements can be of different types.
- A tibble or data frame is a special kind of list (organized by columns with elements of the same class in them)
Use list() to make a list.
- Each element in a list can have many elements (including other lists) in it.
- The length of the list is just how many elements are present at the top level of the list.
$x
[1] "a"
$y
[1] 1
$z
[1] TRUE FALSE TRUE
[[4]]
[[4]][[1]]
[1] "a"
[[4]][[2]]
[1] 1[1] 4The above list, of length 4, has three named elements: a character, a numeric, and a logical vector, and then it has an un-named list as the fourth element.
- The internal unnamed list has two elements
("a", 1)and is also unnamed.
Use str() (for structure) to see the internal properties of a list.
4.3.2 Working with Lists
Single brackets [...] extract a sublist. You use the same extracting strategies as for vectors.
$x
[1] "a"
$y
[1] 1List of 2
$ x: chr "a"
$ y: num 1$y
[1] 1Double brackets [[...]] extract a single list element (which could also be a list).
- Each set of brackets subsets one layer.
[1] "a"[1] TRUE FALSE TRUE logi [1:3] TRUE FALSE TRUE[] or double [[]] when subsetting elements from a list.
Consider the list below.
- Subsetting elements with a single set of brackets always returns a list with one element.
- To remove the list layer, i.e., subset an element as its own structure, you must use two sets of brackets to remove the top layer of the list.
[[1]]
[1] "a"[1] "a"List of 1
$ :'data.frame': 2 obs. of 2 variables:
..$ mpg: num [1:2] 21 21
..$ cyl: num [1:2] 6 6'data.frame': 2 obs. of 2 variables:
$ mpg: num 21 21
$ cyl: num 6 6List of 1
$ :List of 2
..$ : chr "c"
..$ : chr "d"List of 2
$ : chr "c"
$ : chr "d"You can subset multiple elements of different classes with single [] but not multiple elements.
Use dollar signs $ to extract named list elements (like in data frames).
Remove elements of a list by replacing them with NULL.
List of 4
$ x: chr "a"
$ y: num 1
$ z: logi [1:3] TRUE FALSE TRUE
$ :List of 2
..$ : chr "a"
..$ : num 1List of 3
$ y: num 1
$ z: logi [1:3] TRUE FALSE TRUE
$ :List of 2
..$ : chr "a"
..$ : num 14.3.2.1 Exercise
- Create the following list:
- Wario can’t actually make it.
- Remove his row from the data frame.
- Add a new named vector to the list.
- Call it
mealwith the elementsVis"Vegetarian",Cis"Chicken", andBis"Beef".
- Extract the venue and the date from
wedding.
- Use three different techniques to do this.
"chick-fil-a"should be capitalized.
- Capitalize the first
"c"and last"a".
4.4 For-Loops in Base R
4.4.1 Motivation
Iteration is the repetition of some amount of code.
If we didn’t know the
sum()function, how would we add up the elements of a vector?
- We could manually add the elements.
But this is prone to error (especially if we try to copy and paste multiple lines). Also, what if
xhas 10,000 elements?Forloops to the rescue! Here is an example:
4.4.2 For-Loop Structure
For-loops are a standard means in multiple computer languages for iterating (repeating) sections of code for a specified number of iterations (repetitions)
Each for-loop contains the following elements:
- Condition: This sets the number of iterations. It sets the values by which the loops will be sequenced (often by 1) and defines the variable by which the loops will be counted, normally variables such as
i,j, ork.
- In the example above, the function
seq_along(x)is a special version ofseqwhich creates a vector from 1 to the length ofx, incremented by 1 (so1, 2, 3, 4, 5), and the variableiwill contain each successive value from the vector as the loop iterates.
- Body: This is the expression or code between the curly braces
{}. This is the code will be evaluated each iteration with the new value ofifor that iteration. After the end of the expression, the for loop increments the value of the index by the value set in the condition and checks if the loop needs to be run again. If the new value meets the condition, it executes the expression with the new value ofi. If not, the for loop is complete and it moves to the line of code after the closing}of the for loop. - Output: The variable that is produced by the iteration. This is
sumvalabove.
- It’s best to allocate the memory for the output before starting the for-loop.
- Condition: This sets the number of iterations. It sets the values by which the loops will be sequenced (often by 1) and defines the variable by which the loops will be counted, normally variables such as
In the above sequence, R internally transforms the code to:
[1] 16There are four variations on the basic theme of the for loop:
- Modifying an existing object, instead of creating a new object.
- Looping over names or values, instead of indices.
- Handling outputs of unknown length.
- Handling sequences of unknown length.
A best practice for filling a new vector with values is to create it before you run the loop.
- Create the new vector beforehand using the
vector()function by specifying the type (mode) of the elements and the number of elements you need.- Allocating memory is slow so it is faster to do it once before the loop than to add more memory with each iteration of the loop.
- Look at help for
vector()andseq_along().
- You can also create by assigning a vector of
NAs but you should ensure they are of the correct type to avoid conversion during the loop. See help forNA.
For example, let’s calculate a vector of the cumulative sums each element in x.
- The for loop sets the condition and then checks if
i ==1. - If so, it executes the next line. If not, it jumps to the
elseline. - At the end of the expression, it increments
iby1, soi = i +1and goes back to the line with the for loop condition. - It checks if the new value of
istill meets the condition. If so, it executes the expression again. If not, the for loop is done and it jumps to the line of code after the for loop ending}.
[1] 0 0 0 0 0[1] 8 9 12 13 16[1] 8 9 12 13 164.4.2.1 Exercise
- The first two numbers of the Fibonacci Sequence are 0 and 1. Each succeeding number is the sum of the previous two numbers in the sequence. For example, the third element is 0 + 1 = 1, while the fourth element is 1 + 1 = 2, and the fifth element is 2 + 1 = 3 and so on.
Use a for loop to calculate the first 100 Fibonacci Numbers.
As a sanity check: The \(\log_2\) of the 100th Fibonacci Number is about 67.57.
Design your steps - there are two alternatives: Set the first two values inside the loop or set them outside the loop
- Initialize an empty vector of the desired length to hold your numbers
- If you initialize outside the loop, do it now.
- Create your for loop to iterate as many times as you need.
- Create the logic to compute the numbers.
Show code
fibvec <- vector(mode = "double", length = 100)
for (i in seq_along(fibvec)) {
if (i > 2) {
fibvec[[i]] <- fibvec[[i - 1]] + fibvec[[i - 2]]
} else if (i == 1) {
fibvec[[i]] <- 0
} else if (i == 2) {
fibvec[[i]] <- 1
} else {
stop(paste0("i = ", i))
}
}
## Test the results
head(fibvec, n = 10)
log2(fibvec[100])
fibvec <- vector(mode = "double", length = 100)
## initialize outside the loop
fibvec[1:2] <- c(0, 1)
## run the loop skipping the first two numbers
for (i in seq(from = 3, to = length(fibvec))) {
fibvec[[i]] <- fibvec[[i - 1]] + fibvec[[i - 2]]
}
## Test the results
head(fibvec, n = 10)
log2(fibvec[100])4.4.3 Looping Over the Columns of a Data Frame.
For a data frame df, seq_along(df) is the same as 1:ncol(df) which is the same as 1:length(df) (since data frames are special cases of lists).
Let’s calculate the mean of each column of mtcars.
[1] 20.090625 6.187500 230.721875 146.687500 3.596563 3.217250
[7] 17.848750 0.437500 0.406250 3.687500 2.812500 mpg cyl disp hp drat wt qsec
20.090625 6.187500 230.721875 146.687500 3.596563 3.217250 17.848750
vs am gear carb
0.437500 0.406250 3.687500 2.812500 Why not just use colMeans()? Well, you could if you only wanted means.
- However, if you wanted column standard deviations, there is no “
colSDs” function. - Thus you needed some form of iteration for applying custom functions to multiple elements.
For-loops are one method for iteration.
[1] 6.0269481 1.7859216 123.9386938 68.5628685 0.5346787 0.9784574
[7] 1.7869432 0.5040161 0.4989909 0.7378041 1.6152000Good News! With {dplyr} 1.0 we can now use across() as another approach to iteration for many functions.
Let’s load the {tidyverse} which should have {dplyr} version 1.1.2 or greater.
- Look at help for
across()and/or the Column-wise vignette to learn aboutacross()and its counterpartrowwise().
Use across() inside a call to summarize() or mutate().
- Note the
fnargument ofwhere()is the name of the function - do not include the paren operator which “calls” the function.
mpg cyl disp hp drat wt qsec vs
1 6.026948 1.785922 123.9387 68.56287 0.5346787 0.9784574 1.786943 0.5040161
am gear carb
1 0.4989909 0.7378041 1.6152So, you no longer need write a for-loop to do complex summaries of columns, but there are many times when iteration is the best approach to accomplish a desired transformation of the data.
4.4.3.1 Exercise
- Use a for-loop to calculate the standard deviation of the four numeric traits in columns 3 to 6 of the
penguinsdata frame from {palmerpenguins}.
- Repeat using
across()usingwhere()to limit to numeric columns. - What is different about the results?
Show code
data(penguins, package = "palmerpenguins")
sdvec <- rep(NA_real_, length = 4)
for (i in seq_along(sdvec)) {
sdvec[i] <- sd(penguins[[i + 2]], na.rm = TRUE)
}
sdvec
penguins |>
summarize(across(where(is.numeric), .fns = ~ sd(.x, na.rm = TRUE)))
# for loop creates a vector and across creates a data frame.4.4.4 The while() function as an alternative
Sometimes you don’t know how many times to repeat the code block as it may depend upon the results of the loop.
- You might want to loop until you get three heads in a row in a simulation, or,
- You might want to loop until the difference between two values is below or above some threshold.
- You can’t do that sort of iteration with the for-loop. Instead, use a while-loop.
A while loop is simpler than for loop because it only has two components, a condition and a body.
A while-loop is also more general than a for-loop, because you can rewrite any for-loop as a while-loop, but you can’t rewrite every while-loop as a for-loop.
Example: Use a while-loop to find how many tosses of a coin it takes till one gets three heads in a row:
4.5 Using the {purrr} Package for Iteration
4.5.1 Intro to the {purrr} Package
R is a functional programming language
- You can pass functions to functions and use functions to create or change functions.
- You can compose functions together to effect what happens in the environment.
Suppose for the mtcars data frame, we want to calculate the column-wise mean, the column-wise median, the column-wise standard deviation, the column-wise maximum, the column-wise minimum, and the column-wise median absolute deviation MAD.
The for-loop would look very similar for each function fun as shown in this non-executable example.
## Dummy Code with a generic "fun()" function
funvec <- rep(NA_real_, length = length(mtcars))
for (i in seq_along(funvec)) {
funvec[i] <- fun(mtcars[[i]], na.rm = TRUE)
}
funvec- Ideally, we would like to just tell R what function to apply to each column of
mtcarsinstead of writing all the code for a for-loop.
This is exactly what the {purrr} package allows us to do:
- {purrr} provides a consistent syntax for identifying a set of data and then a function to be applied to that data.
- {purrr} is a part of the {tidyverse} package so does not need to be loaded separately.
4.5.2 The {purrr} map Functions
The {purrr} functions that start with map (known as the map*() functions) use the same four arguments
.x: a list or atomic vector with one or more elements..xcan be a vector, a data frame, or a list..f: a function you want to apply to each of the elements of the.xdata structure....: a placeholder for additional arguments to be passed to the.ffunction, e.g.,na.rm=TRUE..progress: ATRUE/FALSElogical for whether to show a progress bar during execution.
The .f functions can be:
a named function from Base R or an R package present in the global environment or accessible using
package::function().a named function you wrote that is accessible in the environment (has been sourced).
an unnamed or “anonymous function” you define inside the
mapfunction. These can include those defined with the new anonymous function shorthand backslash\().
As of version 1.0 (Dec 2022), the the formula syntax with the ~ operator and . pronoun is no longer recommended.
The anonymous function shorthand syntax \(arg) expr with explicit arguments is now recommended.
The map*() functions do the work of running a for-loop for you.
- They create the necessary data structures (and memory) of the desired type.
- They break out the
.xdata structure into its top level elements.- A
.xvector becomes the individual elements of the vector.x[1], .x[2], ... - A
.xdata frame becomes the individual columns of the data frame,df[,1], df[,2], ... - A
.xlist becomes the individual elements of the list, which could be their own individual values, vectors, data frames or lists.
- A
- They iterate to pass each of the individual elements as an input argument to the
.ffunction, e.g.,- the ith element returns the output of
.f(.x[i], ...)as the ith element of the designated output structure.
- the ith element returns the output of
- They return the output in the desired form and type.
- The output has the same number of elements as the original
.xbut may be of a different form, e.g., the.f()function may summarize columns of a data frame into a vector.
- The output has the same number of elements as the original
- The different variants of the
map_*function return different forms of output.map()always returns a list.map_lgl()returns a logical vector.map_int()returns an integer vector.map_dbl()returns a double vector.map_chr()returns a character vector.map_vec()returns an atomic vector for use when.freturns classes such as dates, factors, and date-times. You can use theptype=(prototype) argument to specify the class.
The use of map_* allows you to write succinct code such as the following.
- By using the
...argument, you can pass on more arguments tomap_*()so they can be passed to the.ffunction.
mpg cyl disp hp drat wt qsec
20.090625 6.187500 230.721875 146.687500 3.596563 3.217250 17.848750
vs am gear carb
0.437500 0.406250 3.687500 2.812500 - As an example, you can use
mapto get the output ofsummary()on each column.
- Write code using one of the map functions to:
- Create a character vector with the type of each column in
nycflights13::flights. - Create an integer vector with the number of unique values in each column of
Toothgrowthfrom the base R {datasets} package.
- Create a character vector with the type of each column in
- Repeat 1 and 2 using
dplyr::across()without usingmap*().
Show code
4.5.3 Why Use {purrr}?
The chief benefit of using map*() functions instead of for-loops is clarity, not speed; they can make your code easier to write, read, and maintain as the intent is clearer.
- The focus is on the operation being performed, e.g.,
mean(), not the coding the bookkeeping required to create an output vector, set conditions, loop over every element, and capture the iterated output.
Base R has the apply family of functions that are similar. Using {purrr} functions offers some advantages.
- {purrr} functions have consistent names and arguments and work well with other tidyverse functions.
- The first argument is always the data, so {purrr} works with the pipe.
- {purrr} functions use
.as an argument prefix to avoid inadvertently mixing {purrr} function arguments with those of the.ffunction. - {purrr} functions provide for all combinations of input and output variants and have specific
map2_*functions for the common two argument case. - {purrr} functions are written in C so can be faster than other options.
- See purrr base R for more details.
When performing operations on the columns of a data frame, the dplyr::across()function is an option besides using {purrr}.
4.5.4 {purrr} Functions for Working with Lists
The inherent flexibility of the list data structure can make working with them both necessary and challenging.
- Deeply nested lists are commonly used to capture the complexity of a data set while minimizing redundancy and storage.
- However, deeply nested lists can be hard to operate on with other functions.
Flattening and simplification are operations on lists to expose the data of interest in a convenient form.
Version 1.0 of {purrr} superseded the dfc and dfr functions for creating data frames with three new sets of functions for working with lists:
list_flatten()removes a single level of hierarchy from a list; the output is always a list.- This means it collapses lower level lists into the parent element above them.
list_simplify()reduces a list to a homogeneous vector; the output is always the same length as the input.- This means all the list elements must have length 1.
list_c(), list_cbind(), and list_rbind()concatenate the elements of a list to produce a vector or data frame.list_cconcatenates all the elements into an atomic vector so they must be of the same class.list_cbind()andlist_rbind()only work with lists where every element is a data frame.list_cbind()takes the elements and concatenates them as columns so they must each have of the same length.list_rbind()takes the elements and concatenates them as rows.- If a row is missing a column, it will fill with
NA. - You have to be careful with how names are assigned (see help).
- If a row is missing a column, it will fill with
Example of list_flatten() showing you can use it to keep removing lower level lists until the list is as flat as possible.
List of 2
$ : num 1
$ :List of 3
..$ : num 2
..$ :List of 2
.. ..$ : num 3
.. ..$ : num 4
..$ : num 5List of 4
$ : num 1
$ : num 2
$ :List of 2
..$ : num 3
..$ : num 4
$ : num 5List of 5
$ : num 1
$ : num 2
$ : num 3
$ : num 4
$ : num 5List of 5
$ : num 1
$ : num 2
$ : num 3
$ : num 4
$ : num 5 num [1:5] 1 2 3 4 5Examples of the concatenation functions.
- Let’s create a list of three data frames using
split(). split(.$cyl)is a base R function to turn a data frame into a list of data frames where each data frame has a different value for all units based on thef =argument.- The “
.” insplitreferences the current data frame (sincesplit()is not tidyverse).
- Note the data frames have the same length but different numbers of observations.
List of 3
$ 4:'data.frame': 11 obs. of 11 variables:
..$ mpg : num [1:11] 22.8 24.4 22.8 32.4 30.4 33.9 21.5 27.3 26 30.4 ...
..$ cyl : num [1:11] 4 4 4 4 4 4 4 4 4 4 ...
..$ disp: num [1:11] 108 146.7 140.8 78.7 75.7 ...
..$ hp : num [1:11] 93 62 95 66 52 65 97 66 91 113 ...
..$ drat: num [1:11] 3.85 3.69 3.92 4.08 4.93 4.22 3.7 4.08 4.43 3.77 ...
..$ wt : num [1:11] 2.32 3.19 3.15 2.2 1.61 ...
..$ qsec: num [1:11] 18.6 20 22.9 19.5 18.5 ...
..$ vs : num [1:11] 1 1 1 1 1 1 1 1 0 1 ...
..$ am : num [1:11] 1 0 0 1 1 1 0 1 1 1 ...
..$ gear: num [1:11] 4 4 4 4 4 4 3 4 5 5 ...
..$ carb: num [1:11] 1 2 2 1 2 1 1 1 2 2 ...
$ 6:'data.frame': 7 obs. of 11 variables:
..$ mpg : num [1:7] 21 21 21.4 18.1 19.2 17.8 19.7
..$ cyl : num [1:7] 6 6 6 6 6 6 6
..$ disp: num [1:7] 160 160 258 225 168 ...
..$ hp : num [1:7] 110 110 110 105 123 123 175
..$ drat: num [1:7] 3.9 3.9 3.08 2.76 3.92 3.92 3.62
..$ wt : num [1:7] 2.62 2.88 3.21 3.46 3.44 ...
..$ qsec: num [1:7] 16.5 17 19.4 20.2 18.3 ...
..$ vs : num [1:7] 0 0 1 1 1 1 0
..$ am : num [1:7] 1 1 0 0 0 0 1
..$ gear: num [1:7] 4 4 3 3 4 4 5
..$ carb: num [1:7] 4 4 1 1 4 4 6
$ 8:'data.frame': 14 obs. of 11 variables:
..$ mpg : num [1:14] 18.7 14.3 16.4 17.3 15.2 10.4 10.4 14.7 15.5 15.2 ...
..$ cyl : num [1:14] 8 8 8 8 8 8 8 8 8 8 ...
..$ disp: num [1:14] 360 360 276 276 276 ...
..$ hp : num [1:14] 175 245 180 180 180 205 215 230 150 150 ...
..$ drat: num [1:14] 3.15 3.21 3.07 3.07 3.07 2.93 3 3.23 2.76 3.15 ...
..$ wt : num [1:14] 3.44 3.57 4.07 3.73 3.78 ...
..$ qsec: num [1:14] 17 15.8 17.4 17.6 18 ...
..$ vs : num [1:14] 0 0 0 0 0 0 0 0 0 0 ...
..$ am : num [1:14] 0 0 0 0 0 0 0 0 0 0 ...
..$ gear: num [1:14] 3 3 3 3 3 3 3 3 3 3 ...
..$ carb: num [1:14] 2 4 3 3 3 4 4 4 2 2 ...list_c()concatenates the three data frames from the list back into one data frame.
mpg cyl disp hp drat wt qsec vs am gear carb
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1list_rbind()concatenates the three data frames from the list back into one data frame as well since they have the same column structure.
mpg cyl disp hp drat wt qsec vs am gear carb
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1list_cbind()generates an error as the three data frames from the list have different numbers of rows so can’t fit in the same column structure.
This example from the list_cbind()help shows that list_cbind() returns a data frame with packed columns where the packed data frames retain the names of the original list elements and their columns retain the names from the original data frame.
- You can still access these columns directly though the names and subsetting.
'data.frame': 2 obs. of 2 variables:
$ a:'data.frame': 2 obs. of 1 variable:
..$ x: int 1 2
$ b:'data.frame': 2 obs. of 1 variable:
..$ y: chr "a" "a"[1] "a" "b"'data.frame': 2 obs. of 1 variable:
$ x: int 1 2[1] "x" x
1 1
2 2 x
1 1
2 2You can also unpack the data frame columns with tidyr::unpack().
- Again you have to be careful with how to manage the names.
tibble [2 × 2] (S3: tbl_df/tbl/data.frame)
$ x: int [1:2] 1 2
$ y: chr [1:2] "a" "a"[1] "x" "y"[1] 1 2This example shows list_cbind() with a larger data set, dplyr::starwars.
- We drop the list columns (12-14) as they cannot be converted to data frames.
Rows: 87
Columns: 14
$ name <chr> "Luke Skywalker", "C-3PO", "R2-D2", "Darth Vader", "Leia Or…
$ height <int> 172, 167, 96, 202, 150, 178, 165, 97, 183, 182, 188, 180, 2…
$ mass <dbl> 77.0, 75.0, 32.0, 136.0, 49.0, 120.0, 75.0, 32.0, 84.0, 77.…
$ hair_color <chr> "blond", NA, NA, "none", "brown", "brown, grey", "brown", N…
$ skin_color <chr> "fair", "gold", "white, blue", "white", "light", "light", "…
$ eye_color <chr> "blue", "yellow", "red", "yellow", "brown", "blue", "blue",…
$ birth_year <dbl> 19.0, 112.0, 33.0, 41.9, 19.0, 52.0, 47.0, NA, 24.0, 57.0, …
$ sex <chr> "male", "none", "none", "male", "female", "male", "female",…
$ gender <chr> "masculine", "masculine", "masculine", "masculine", "femini…
$ homeworld <chr> "Tatooine", "Tatooine", "Naboo", "Tatooine", "Alderaan", "T…
$ species <chr> "Human", "Droid", "Droid", "Human", "Human", "Human", "Huma…
$ films <list> <"A New Hope", "The Empire Strikes Back", "Return of the J…
$ vehicles <list> <"Snowspeeder", "Imperial Speeder Bike">, <>, <>, <>, "Imp…
$ starships <list> <"X-wing", "Imperial shuttle">, <>, <>, "TIE Advanced x1",…'data.frame': 87 obs. of 11 variables:
$ name :'data.frame': 87 obs. of 1 variable:
..$ x: chr "Luke Skywalker" "C-3PO" "R2-D2" "Darth Vader" ...
$ height :'data.frame': 87 obs. of 1 variable:
..$ x: int 172 167 96 202 150 178 165 97 183 182 ...
$ mass :'data.frame': 87 obs. of 1 variable:
..$ x: num 77 75 32 136 49 120 75 32 84 77 ...
$ hair_color:'data.frame': 87 obs. of 1 variable:
..$ x: chr "blond" NA NA "none" ...
$ skin_color:'data.frame': 87 obs. of 1 variable:
..$ x: chr "fair" "gold" "white, blue" "white" ...
$ eye_color :'data.frame': 87 obs. of 1 variable:
..$ x: chr "blue" "yellow" "red" "yellow" ...
$ birth_year:'data.frame': 87 obs. of 1 variable:
..$ x: num 19 112 33 41.9 19 52 47 NA 24 57 ...
$ sex :'data.frame': 87 obs. of 1 variable:
..$ x: chr "male" "none" "none" "male" ...
$ gender :'data.frame': 87 obs. of 1 variable:
..$ x: chr "masculine" "masculine" "masculine" "masculine" ...
$ homeworld :'data.frame': 87 obs. of 1 variable:
..$ x: chr "Tatooine" "Tatooine" "Naboo" "Tatooine" ...
$ species :'data.frame': 87 obs. of 1 variable:
..$ x: chr "Human" "Droid" "Droid" "Human" ... [1] "name" "height" "mass" "hair_color" "skin_color"
[6] "eye_color" "birth_year" "sex" "gender" "homeworld"
[11] "species" # A tibble: 87 × 11
namex heightx massx hair_colorx skin_colorx eye_colorx birth_yearx sexx
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 Luke Skyw… 172 77 blond fair blue 19 male
2 C-3PO 167 75 <NA> gold yellow 112 none
3 R2-D2 96 32 <NA> white, blue red 33 none
4 Darth Vad… 202 136 none white yellow 41.9 male
5 Leia Orga… 150 49 brown light brown 19 fema…
6 Owen Lars 178 120 brown, grey light blue 52 male
7 Beru Whit… 165 75 brown light blue 47 fema…
8 R5-D4 97 32 <NA> white, red red NA none
9 Biggs Dar… 183 84 black light brown 24 male
10 Obi-Wan K… 182 77 auburn, wh… fair blue-gray 57 male
# ℹ 77 more rows
# ℹ 3 more variables: genderx <chr>, homeworldx <chr>, speciesx <chr>4.5.4.1 Exercise
Generate a data frame where the rows are sample of 10 random values from a Normal\((\mu, 1)\) distributions for each of element in the sequence \(\mu = -10, 0, 10, \ldots, 100\).
4.5.5 Using map_* to Create Models and Extract Values
Consider the following chunk of code which allows us to fit many simple linear regression models:
splitconverts the data framemtcarsinto a list with three data frames as elements based on the three levels ofcyl.function(df) lm(mpg ~ wt, data = df)defines an “anonymous function” to fit a linear model ofmpgonwtbased on the variables in the data framedfpassed to it (bymap()) as an input argument.- It returns as output a list of three
lmobjects you can use to get fitted values and summaries.
Call:
lm(formula = mpg ~ wt, data = df)
Residuals:
Min 1Q Median 3Q Max
-4.1513 -1.9795 -0.6272 1.9299 5.2523
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 39.571 4.347 9.104 7.77e-06 ***
wt -5.647 1.850 -3.052 0.0137 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.332 on 9 degrees of freedom
Multiple R-squared: 0.5086, Adjusted R-squared: 0.454
F-statistic: 9.316 on 1 and 9 DF, p-value: 0.01374Since the output of map() is a list, we can then use map() to generate a list with the summary() for each linear model object.
Extracting named elements is a common operation, so {purrr} provides a shortcut; you can use a string.
[1] 0.5086326 4 6 8
0.5086326 0.4645102 0.4229655 $`4`
value numdf dendf
9.316233 1.000000 9.000000
$`6`
value numdf dendf
4.337245 1.000000 5.000000
$`8`
value numdf dendf
8.795985 1.000000 12.000000 You can also use an integer to select elements by position:
4.5.6 Building map Expressions (Backwards) from an Example
It can be daunting at first to think through how to build a map expression from left to right. As an alternative, consider working from right to left.
- Write the code to do just one element of the
.xinput data. - Once that works, convert it to an anonymous function using
\(arg)where you put in a dummy argument representing the element - Wrap the anonymous function with
map()with the.x(perhaps piped in).
- Since
map()always returns a list, think about what kind of output you want and consider differentmap_*()variants, e.g.,map_df()ormap_dfr(),map_lgl(), etc.. - If you don’t want the
mapcode to operate on every element of the.xinput, then consider using themap_if()function for conditional execution on an element.
- We often use a \(t\)-test to test if differences in population means are “real”. R implements this with
t.test().
- For example, to test for differences between the mean
mpgof automatics and manuals (coded in variableam), we would use the following syntax. Note, the output oft.test()is a list.
- Use
split()to create three subsets ofmtcarsand then try the backwards approach to build amap()expression to conduct the t.test on each subset. - Pipe to a map expression to get a vector of the \(p\)-values for each subset of
cyl.
4.5.7 map2() and pmap() Enable Mapping over Multiple Arguments in Parallel
If you have multiple related input vectors you need to iterate along in parallel, that’s the job of the map2() and pmap() functions.
Example: you want to simulate five random draws from three different Normal distributions with different means and variances.
- You could iterate over the indices of the inputs using
seq_along()and index into vectors of means and standard deviations:
List of 3
$ : num [1:5] 0.374 1.184 0.164 2.595 1.33
$ : num [1:5] 95.9 102.4 103.7 102.9 98.5
$ : num [1:5] 20.2 -2.2 -22.4 -54.3 12.5That can be confusing code to read, so {purrr} provides the function map2().
map2()has arguments for.xand.y.- They should be of the same length or one can be of length 1 which is recycled.
List of 3
$ : num [1:5] 0.374 1.184 0.164 2.595 1.33
$ : num [1:5] 95.9 102.4 103.7 102.9 98.5
$ : num [1:5] 20.2 -2.2 -22.4 -54.3 12.5 mu_1_sigma_1 mu_100_sigma_5 mu_.10_sigma_20
1 0.9550664 104.59489 -11.122575
2 0.9838097 103.91068 -13.115910
3 1.9438362 100.37282 -39.415048
4 1.8212212 90.05324 -19.563001
5 1.5939013 103.09913 -1.641169When you have multiple vectors to iterate over, purrr::pmap() handles more than two vectors.
- Instead of
.xand.y, there is a.largument for a list of inputs.
Suppose we want a different number of samples from the three distributions.
- We create a list of our arguments: Three distributions and three arguments for each distribution.
- That becomes our the
.largument (instead of.x).
List of 3
$ n :List of 3
..$ : num 20
..$ : num 30
..$ : num 50
$ mean:List of 3
..$ : num 1
..$ : num 100
..$ : num -10
$ sd :List of 3
..$ : num 1
..$ : num 5
..$ : num 20List of 3
$ : num [1:20] 2.359 0.897 1.388 0.946 -0.377 ...
$ : num [1:30] 102 96.9 101.7 94.4 107.2 ...
$ : num [1:50] -21.37 -12.7 13.56 -40.47 1.88 ...4.5.8 {purrr} keep() and discard() Select Columns with Logicals
keep() selects all variables that return TRUE according to a function you choose or define.
- It is similar in concept to select with
tidyr_tidy_selectfunctions
Example: let’s keep all numeric variables in the starwars data frame and calculate their means as a vector.
height mass birth_year
174.60494 97.31186 87.56512 discard() will select all variables that return FALSE according to some function.
Let’s get the summary for each column that is not a list or character.
name height mass hair_color skin_color eye_color
"character" "integer" "numeric" "character" "character" "character"
birth_year sex gender homeworld species films
"numeric" "character" "character" "character" "character" "list"
vehicles starships
"list" "list" $height
Min. 1st Qu. Median Mean 3rd Qu. Max. NAs
66.0 167.0 180.0 174.6 191.0 264.0 6
$mass
Min. 1st Qu. Median Mean 3rd Qu. Max. NAs
15.00 55.60 79.00 97.31 84.50 1358.00 28
$birth_year
Min. 1st Qu. Median Mean 3rd Qu. Max. NAs
8.00 35.00 52.00 87.57 72.00 896.00 44 4.5.8.1 Exercise
- In the
mtcarsdata frame, use only three lines of code to create a vector with the mean of only the variables that have a mean greater than10.
4.5.9 {purrr} keep_at() and discard_at() Select Columns with Names
These functions work similar to keep() and discard() only the predicate arguments use the column names as input.
You can use a character vector of the names.
height mass
174.60494 97.31186 You can use an anonymous function of the names, e.g., with str_detect().
# A tibble: 87 × 3
hair_color skin_color eye_color
<chr> <chr> <chr>
1 blond fair blue
2 <NA> gold yellow
3 <NA> white, blue red
4 none white yellow
5 brown light brown
6 brown, grey light blue
7 brown light blue
8 <NA> white, red red
9 black light brown
10 auburn, white fair blue-gray
# ℹ 77 more rowsYou can use your own named function and also pipe to other functions.
[1] FALSE FALSE FALSE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
[13] FALSE FALSERows: 87
Columns: 7
$ name <chr> "Luke Skywalker", "C-3PO", "R2-D2", "Darth Vader", "Leia Org…
$ height <int> 172, 167, 96, 202, 150, 178, 165, 97, 183, 182, 188, 180, 22…
$ mass <dbl> 77.0, 75.0, 32.0, 136.0, 49.0, 120.0, 75.0, 32.0, 84.0, 77.0…
$ sex <chr> "male", "none", "none", "male", "female", "male", "female", …
$ gender <chr> "masculine", "masculine", "masculine", "masculine", "feminin…
$ homeworld <chr> "Tatooine", "Tatooine", "Naboo", "Tatooine", "Alderaan", "Ta…
$ species <chr> "Human", "Droid", "Droid", "Human", "Human", "Human", "Human…4.5.10 Get or Set an Element Deep in a Nested Data Structure
The {purrr package} has a function called pluck() which you can use to get or set elements deep within nested lists or data frames without having to manipulate the entire nested data structure.
pluck() is a shorthand way of combining multiple subset operators [].
- pluck() provides a way of retrieving objects from such data structures using a combination of numeric positions, vectors, or list names.
In our starwars example we can go the the films column, which is a list, and get the 4th element of the first row.
4.5.11 {purrr} Summary
The {purrr} package facilitates functional programming with functions for working with vectors and for using functions as arguments for other functions.
- The
map_*functions take care of iterating through code so you don’t have to write for-loops. - They can streamline your code, making it easier to interpret and maintain.
Learning the {purrr} functions can be a good use of your time as you work with more complicated data sets.