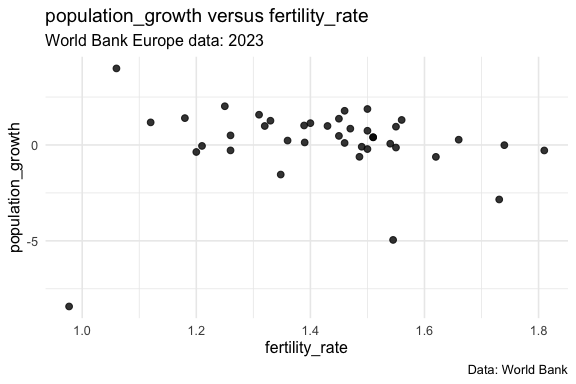
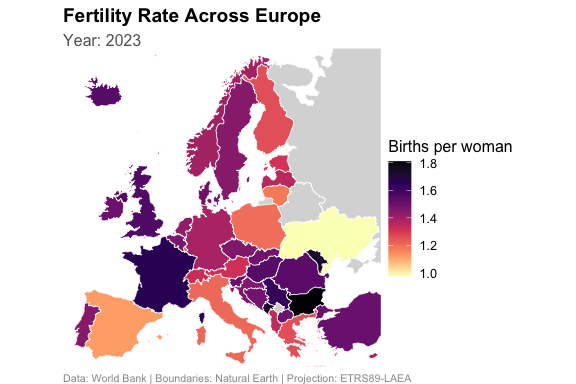
A Grammar of Animated Graphics. n.d. Accessed May 22, 2026.
https://gganimate.com/.
“albertocairo.” n.d. In
albertocairo. Accessed May 22, 2026.
https://www.albertocairo.com.
Anthropic. 2025.
Claude.
https://claude.ai.
Anthropic. n.d.-a.
“Best Practices for Claude Code.” In
Claude Code Docs. Accessed April 13, 2026.
https://code.claude.com/docs/en/best-practices.
Anthropic. n.d.-b.
“Claude Code Overview.” In
Claude Code Docs. Accessed April 16, 2026.
https://code.claude.com/docs/en/overview.
Anthropic Engineering. n.d.-a.
“Complete Context Engineering Guide.” In
Claude. Accessed April 6, 2026.
https://claude.ai/public/artifacts/f498a4cc-4c45-481c-a6dd-8e1d196dadb0.
Anthropic Engineering. n.d.-b.
“Prompt Engineering Overview.” In
Claude API Docs. Accessed April 10, 2026.
https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/overview.
Anthropic Engineering. n.d.-c.
“Prompting Best Practices.” In
Claude API Docs. Accessed April 6, 2026.
https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/claude-prompting-best-practices.
API Basic Call Structures – World Bank Data Help Desk. n.d. Accessed June 1, 2026.
https://datahelpdesk.worldbank.org/knowledgebase/articles/898581.
ASA, American Statistical Association. 1983.
Auto Data Set from the 1983 Exposition of Statistical Graphics Technology.
https://lib.stat.cmu.edu/data-expo/1983.html.
AWS. n.d.
“What Is RAG? - Retrieval-Augmented Generation AI Explained - AWS.” In
Amazon Web Services, Inc. Accessed June 5, 2026.
https://aws.amazon.com/what-is/retrieval-augmented-generation/.
Barret, Tyson, Matt Dowle, Arun Srinivasan, et al. 2025.
Data.table: Extension of ‘Data.frame‘.
https://r-datatable.com.
Bartley, Kevin. 2024.
“Data Statistics (2025) - How Much Data Is There in the World?” In
Rivery.
https://rivery.io/blog/big-data-statistics-how-much-data-is-there-in-the-world/.
Brown, Tom B., Benjamin Mann, Nick Ryder, et al. 2020.
Language Models Are Few-Shot Learners. arXiv:2005.14165. arXiv.
https://doi.org/10.48550/arXiv.2005.14165.
Chang, Winston. n.d.
R Graphics Cookbook, 2nd Edition. Accessed May 22, 2026.
https://r-graphics.org/.
Chat with Large Language Models. n.d. Accessed August 15, 2025.
https://ellmer.tidyverse.org/index.html.
“Claude Code Create Custom Subagents.” n.d. In
Claude Code Docs. Accessed April 19, 2026.
https://code.claude.com/docs/en/sub-agents.
“Claude Code Define Your Agent.” n.d. In
Claude API Docs. Accessed April 19, 2026.
https://platform.claude.com/docs/en/managed-agents/agent-setup.
Codex AI Assistant for Work and Code. n.d. Accessed June 8, 2026.
https://chatgpt.com/codex/.
Csardi, Garbor. 2022.
Keyring: Access the System Credential Store from R.
https://r-lib.github.io/keyring/index.html.
DAIR-AI. 2025.
Prompt Engineering Guide.
https://www.promptingguide.ai/.
Davenport, Thomas H., and D J. Patil. 2012.
“Data Scientist: The Sexiest Job of the 21st Century.” Harvard Business Review October 2012: 70–76.
http://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century/ar/1.
Eurostat. n.d.
Data Access via API - User Guides. Accessed June 1, 2026.
https://ec.europa.eu/eurostat/web/user-guides/data-browser/api-data-access.
Fox, John, and Sanford Weisberg. 2019.
An Companion to Applied Regression. Third. Sage.
https://www.john-fox.ca/Companion/.
Friedman, Jerome, Trevor Hastie, and Robert Tibshirani. 2010.
“Regularization Paths for Generalized Linear Models via Coordinate Descent.” Journal of Statistical Software 33 (1): 1–22.
https://doi.org/10.18637/jss.v033.i01.
Gábor Csárdi. 2023.
Gitcreds: Query ’Git’ Credentials from ’R’.
https://gitcreds.r-lib.org/.
Ggrepel: An R Package. n.d. Accessed May 22, 2026.
https://ggrepel.slowkow.com/.
Godsey, Brian. 2017. Think Like a Data Scientist. Manning.
Google. n.d.
Agent Development Kit (ADK). Accessed April 19, 2026.
https://adk.dev.
Grolemund, Garrett, and Hadley Wickham. 2011.
“Lubridate: Dates and Times Made Easy with Lubridate.” Journal of Statistical Software 40 (3): 1–25.
https://www.jstatsoft.org/v40/i03/.
Grolemund, Garrett, and Hadley Wickham. n.d.
R for Data Science.
https://r4ds.had.co.nz/.
Groq. n.d.
API Reference - GroqDocs. Accessed June 4, 2026.
https://console.groq.com/docs/api-reference#chat-create.
Hadley Wickham. 2016.
Ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York.
https://ggplot2.tidyverse.org/.
Hadley Wickham, Danielle Navarro, and Thomas Lin Pedersen. n.d.
Ggplot2: Elegant Graphics for Data Analysis (3e). Accessed May 22, 2026.
https://ggplot2-book.org/.
Horst, Allison, Alison Presmanes Hill, and Kristen B Gorman. 2020.
Palmerpenguins R Data Package.
https://doi.org/10.5281/zenodo.3960218.
Ian Fellows. 2022.
Wordcloud: Word Clouds. Comprehensive R Archive Network.
https://doi.org/10.32614/CRAN.package.wordcloud.
Institute of Statistics (INSTAT). 2025.
Statistical Database.
https://databaza.instat.gov.al:8083/pxweb/en/DST/.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2023.
An Introduction to Statistical Learning with Applications in R. 2nd ed. Springer.
https://www.statlearning.com.
Kalinowski, Tomasz et al. 2022.
TensorFlow for R.
https://tensorflow.rstudio.com/.
Kalinowski, Tomasz, JJ Allaire, and François Chollet. 2025.
Keras3: R Interface to Keras.
https://keras3.posit.co/.
Kanwal, Maxinder S., Avinash S. Ramesh, and Lauren A. Huang. 2013.
A Novel Pseudoderivative-Based Mutation Operator for Real-Coded Adaptive Genetic Algorithms. 2:139. F1000Research.
https://doi.org/10.12688/f1000research.2-139.v2.
Karatzoglou, Alexandros, Alex Smola, Kurt Hornik, National ICT Australia (NICTA), Michael A. Maniscalco, and Choon Hui Teo. 2024.
Kernlab: Kernel-Based Machine Learning Lab.
https://CRAN.R-project.org/package=kernlab.
Kelechava, Brad. 2018.
“The SQL Standard - ISO/IEC 9075:2023 (ANSI X3.135).” In
The ANSI Blog.
https://blog.ansi.org/sql-standard-iso-iec-9075-2023-ansi-x3-135/.
Keras: Deep Learning for Humans. n.d. Accessed May 28, 2026.
https://keras.io/.
Khun, Max, and Julia Silge. 2023.
Tidy Modeling with R.
https://www.tmwr.org/.
Kingma, Diederik P., and Jimmy Ba. 2017.
Adam: A Method for Stochastic Optimization. arXiv:1412.6980. arXiv.
https://doi.org/10.48550/arXiv.1412.6980.
Kuhn, Max, and Hadley Wickham. 2020.
Tidymodels: A Collection of Packages for Modeling and Machine Learning Using Tidyverse Principles. https://www.tidymodels.org.
Lin, Hause, and Tawab Safi. 2025.
“Ollamar: An R Package for Running Large Language Models.” Journal of Open Source Software, ahead of print.
https://doi.org/10.21105/joss.07211.
Luo, Junyu. 2026.
Luo-Junyu/Awesome-Agent-Papers.
https://github.com/luo-junyu/Awesome-Agent-Papers.
Luo, Junyu, Weizhi Zhang, Ye Yuan, et al. 2025.
Large Language Model Agent: A Survey on Methodology, Applications and Challenges. arXiv:2503.21460. arXiv.
https://doi.org/10.48550/arXiv.2503.21460.
Mark Lodato. n.d.
A Visual Git Reference. Accessed May 30, 2026.
https://marklodato.github.io/visual-git-guide/index-en.html.
Mei, Lingrui, Jiayu Yao, Yuyao Ge, et al. 2025.
“A Survey of Context Engineering for Large Language Models.” In
arXiv.org.
https://arxiv.org/abs/2507.13334v2.
Mosaic Plots in the Ggplot2 Framework. n.d. Accessed May 22, 2026.
https://haleyjeppson.github.io/ggmosaic/.
Myer, David. 2024.
E1071: Misc Functions of the Department of Statistics, Probability Theory Group.
https://cran.r-project.org/web/packages/e1071.
Neal Richardson, Ian Cook, Nic Crane, et al. 2026.
Arrow: Integration to ’Apache’ ’Arrow’.
https://github.com/apache/arrow/.
Ooms, Jeroen. 2014.
“Jsonlite: The Jsonlite Package: A Practical and Consistent Mapping Between JSON Data and R Objects.” arXiv:1403.2805 [Stat.CO].
https://arxiv.org/abs/1403.2805.
Ooms, Jeroen. 2023.
Jasonlite Vignette: Getting Started with JSON and Jsonlite.
https://cran.r-project.org/web/packages/jsonlite/vignettes/json-aaquickstart.html.
Open Data Inventory—Global Index of Open Data - Open Data Inventory. n.d. Accessed May 8, 2025.
https://odin.opendatawatch.com/.
OpenAI Developers. n.d.
Agents SDK. Accessed April 16, 2026.
https://developers.openai.com/api/docs/guides/agents.
OWASP Foundation. n.d.
Least Privilege Principle. Accessed April 19, 2026.
https://owasp.org/www-community/controls/Least_Privilege_Principle.
Pebesma, Edzer. 2018.
“Sf: Simple Features for R: Standardized Support for Spatial Vector Data.” The R Journal 10 (1): 439–46.
https://r-spatial.github.io/sf/.
Plaat, Aske, Max van Duijn, Niki van Stein, Mike Preuss, Peter van der Putten, and Kees Joost Batenburg. 2025.
“Agentic Large Language Models, a Survey.” In
arXiv.org.
https://doi.org/10.1613/jair.1.18675.
Plotly r Graphing Library in R. n.d. Accessed May 23, 2026.
https://plotly.com/r/.
Posit. 2025c.
“RStudio IDE User Guide.” In
RStudio User Guide.
https://docs.posit.co/ide/user/.
Posit. 2026.
“Quarto Guide.” In
Quarto.
https://quarto.org/docs/guide/.
Posit. n.d.
Posit Assistant. Accessed June 10, 2026.
https://posit-dev.github.io/assistant/.
Positron. n.d.-a.
“Guide for Positron Assistant.” In
Positron. Accessed April 18, 2026.
https://positron.posit.co/assistant.html.
Positron. n.d.-b.
“Positron Assistant Getting Started.” In
Positron. Accessed April 18, 2026.
https://positron.posit.co/assistant-getting-started.html.
Quarto. 2025. Posit.co.
https://quarto.org/.
Rashida048. 2020.
Machine Learning: Gradient Descent Concept – Regenerative.
https://regenerativetoday.com/machine-learning-gradient-descent-concept/.
Robinson, Julia Silge and David. n.d.
Text Mining with R. Accessed April 12, 2020.
https://www.tidytextmining.com/.
Sahoo, Pranab, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024.
“A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications.” In
arXiv.org.
https://arxiv.org/abs/2402.07927v2.
Silge, Julia, and David Robinson. 2023.
Tidytext: Text Mining Using Tidy Tools.
https://juliasilge.github.io/tidytext/.
Silge, Julia, and David Robinson. 2025.
Tidytext: Text Mining with R. O’Reilly Media, Inc.
https://www.tidytextmining.com/.
Sjoberg, Daniel D., Karissa Whiting, Michael Curry, Jessica A. Lavery, and Joseph Lamarange. 2021.
“Reproducible Summary Tables with the Gtsummary Package.” The R Journal 13 (1): 570–80.
https://doi.org/10.32614/RJ-2021-053.
Stryker, Ivan Belcic, Cole. 2024.
What Is Data Engineering? IBM.
https://www.ibm.com/think/topics/data-engineering.
Takeda, Hajime. 2026.
“How to Build a Production-Ready Claude Code Skill.” In
Towards Data Science.
https://towardsdatascience.com/how-to-build-a-production-ready-claude-code-skill/.
Team, R Core. 2018.
R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing.
https://www.R-project.org/.
“TensorFlow.” n.d. In
TensorFlow. Accessed May 28, 2026.
https://www.tensorflow.org/.
The Composer of Plots. n.d. Accessed May 22, 2026.
https://patchwork.data-imaginist.com/.
“The Visual Display of Quantitative Information.” n.d. In
Edward Tufte. Accessed May 22, 2026.
https://www.edwardtufte.com/book/the-visual-display-of-quantitative-information/.
Ushey, Kevin, JJ Allaire, and Yuan Tang. 2023.
Reticulate: R Interface to Python.
https://rstudio.github.io/reticulate/.
van Rossum, Guido. 2025.
Python.
https://www.python.org/.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, et al. 2023.
Attention Is All You Need. arXiv:1706.03762. arXiv.
https://doi.org/10.48550/arXiv.1706.03762.
VoltAgent/Awesome-Claude-Code-Subagents. 2026. VoltAgent.
https://github.com/VoltAgent/awesome-claude-code-subagents.
Waring, Elin, Michael Quinn, Amelia McNamara, Eduardo Arino d la RUbia, Shu Hao, and Shannon Ellis. 2025.
Skimr: Compact and Flexible Summaries of Data.
https://docs.ropensci.org/skimr/.
“What Is the Model Context Protocol (MCP)?” n.d. In
Model Context Protocol. Accessed June 10, 2026.
https://modelcontextprotocol.io/docs/getting-started/intro.
Wickham, Hadley. 2010.
“A Layered Grammar of Graphics.” Journal of Computational and Graphical Statistics 19 (1): 3–28.
https://doi.org/10.1198/jcgs.2009.07098.
Wickham, Hadley. 2016.
Ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York.
https://ggplot2.tidyverse.org/.
Wickham, Hadley. 2023a.
Forcats: Tools for Working with Categorical Variables (Factors).
https://forcats.tidyverse.org/.
Wickham, Hadley. 2023b.
Httr2: Perform HTTP Requests and Process the Responses.
https://httr2.r-lib.org/.
Wickham, Hadley. 2023c.
Modelr: Modelling Functions That Work with the Pipe.
https://modelr.tidyverse.org/.
Wickham, Hadley. 2023d.
Stringr: Simple, Consistent Wrappers for Common String Operations.
https://stringr.tidyverse.org/.
Wickham, Hadley, Mara Averick, Jennifer Bryan, et al. 2019.
“Welcome to the Tidyverse.” Journal of Open Source Software, no. 43: 1686.
https://doi.org/10.21105/joss.01686.
Wickham, Hadley, and Jennifer Bryan. 2023.
Readxl: Read Excel Files.
https://readxl.tidyverse.org.
Wickham, Hadley, Mine Cetinkaya-Rundel, and Garrett Grolemund. 2023.
R for Data Science (2e). O’Reilly Media, Inc.
https://r4ds.hadley.nz/.
Wickham, Hadley, Romain Francois, Lionel Henry, Kirill Muller, and Davis Vaughan. 2023.
Dplyr: A Grammar of Data Manipulation.
https://dplyr.tidyverse.org.
Wickham, Hadley, Jim Hester, and Jennifer Bryan. 2024.
Readr: Read Rectangular Text Data.
https://readr.tidyverse.org/.
Wickham, Hadley, Davis Vaughan, and Maximilian Girlich. 2023.
Tidyr: Tidy Messy Data.
https://tidyr.tidyverse.org.
Wikipedia. 2025.
“Data Science.” In
Wikipedia.
https://en.wikipedia.org/wiki/Data_science.