9 Neural Networks
Neural Networks, Layers, Weights, Biases, Back Propagation, reticulate, TensorFlow, Keras, Colab, CNNs
9.1 Introduction
This module introduces neural networks and the basics of their structure and algorithms.
Learning Outcomes
- Explain the basic architecture of a neural network.
- Describe the the differences between Regression and Classification Neural Networks
- Explain the role of back-propagation and gradient descent in training.
- Explore Neural Networks using Google Colab
- Describe a Convolutional Neural Network.
- Describe approaches for using pre-trained Neural Networks
- Describe considerations for responsible use of Neural Networks
9.1.1 References
9.2 Neural Networks
Deep Learning and Neural Nets are two terms that describe a set of machine learning methods that build networks with one or more layers of calculations to manipulate input data to derive outputs.
- The Deep in Deep Learning refers to the use of multiple layers in the networks. The more layers of calculations, the deeper the network.
- The Neural in Neural Networks (Neural Nets) refers to the use of methods called Artificial Neural Networks whose design is inspired by or emulates the actions of nerves in animals.
- Nerves receive inputs from multiple chemical signals and when the level of signal crosses a threshold, the nerve can “fire”.
- When a nerve reaches its action potential and fires, it sends electro-chemical signals cascading down the nerve to generate outputs.
- These outputs generate input signals to other (nearby) nerves (or other cells).
- These signals can either trigger the activation in nearby nerves or suppress their activation.
- The outputs may also cause a cell to take or suppress a given activity.
- Figure 9.1 shows an image of several nerve cells and their growing network of connections across the brain.
For more insights into animal neurons and their firing, see the following video (2-Minute Neuroscience 2014)
Deep Learning methods can used for supervised or unsupervised learning.
They tend to require lots of input data and many calculations so their development has expanded greatly in the last few years given the large increases in available data and affordable computing power. (Figure 9.2)
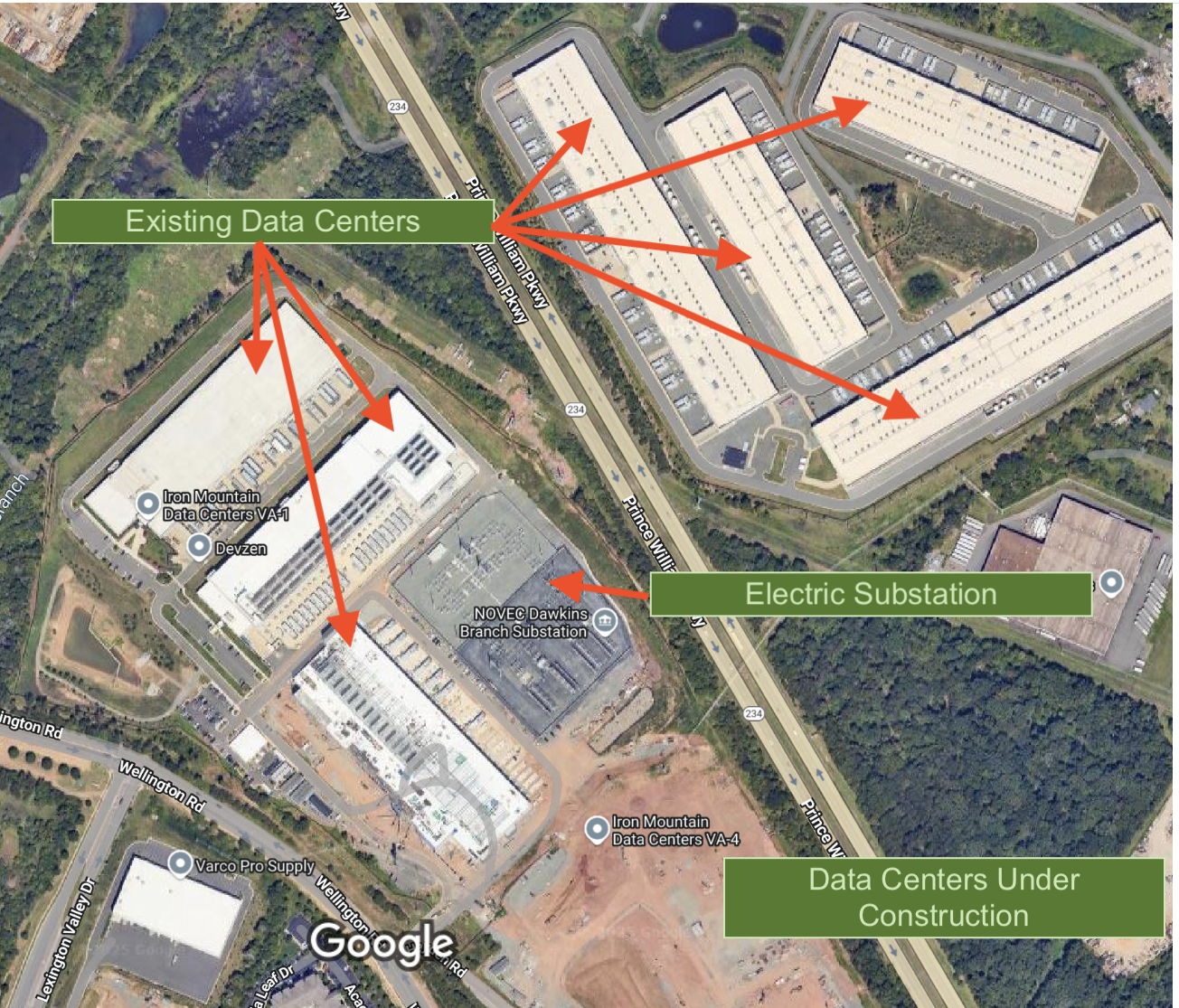
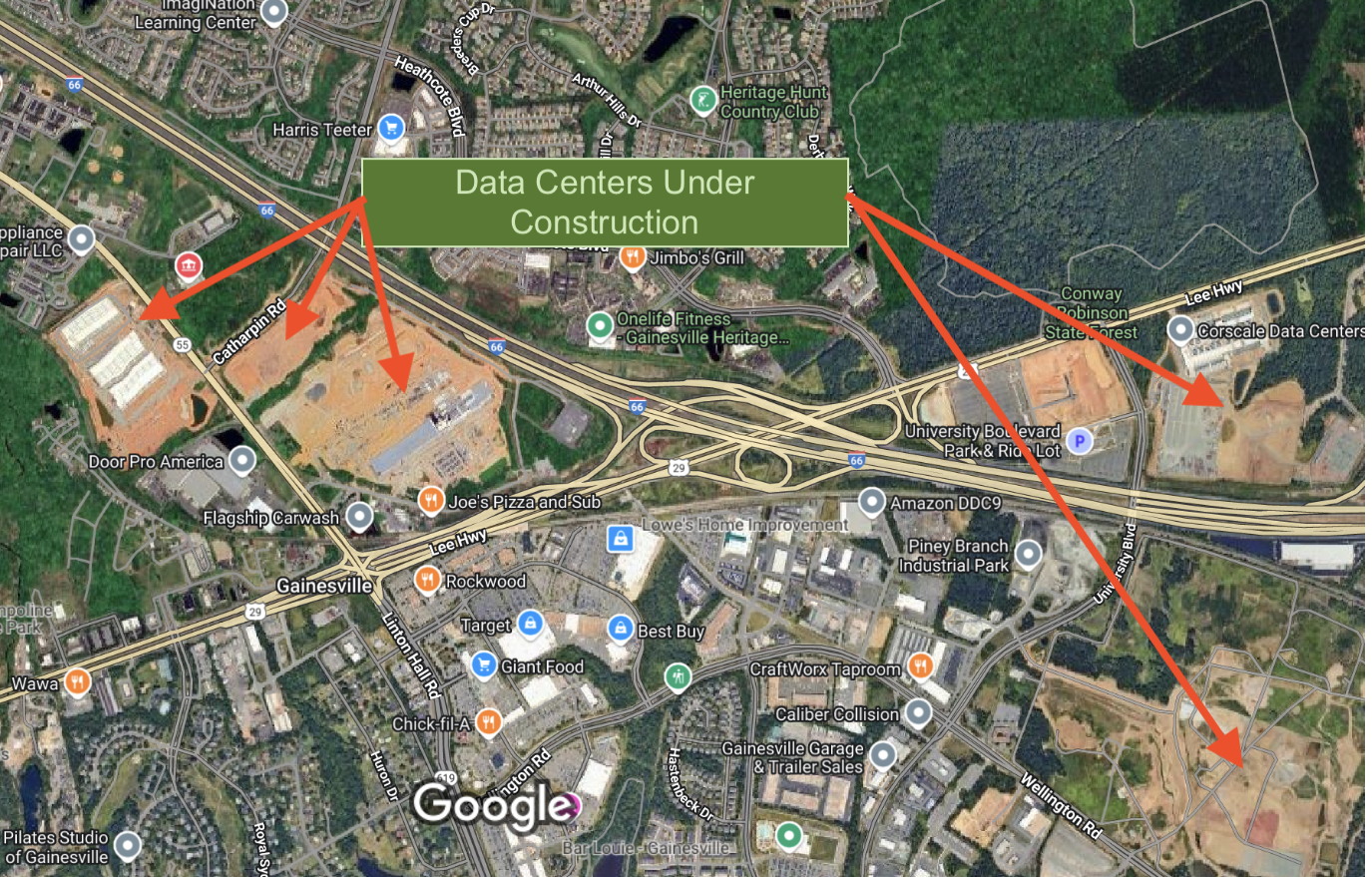
A single modern 30 MW hyperscale data center building consumes electricity on the same order of magnitude as the entire city of Vlorë.
- Depending on actual utilization, it could use anywhere from about 70% to nearly 100% of Vlorë’s electricity demand.
- The entire planned Iron Mountain campus in Manassas, VA (280 MW) (Figure 9.2 (a) a) would consume approximately \(2.45 \text{ TWh/year}\) which is roughly one-third of all electricity consumed in Albania in a year.
- There are 59 data centers operating in Prince William county now and they consume as much electric power as Greece.
- There are plans to build at least 15 more campuses and a high-capacity power line system which could together could consume more than \(230 \text{ TWh/year}\) which is greater than the combined consumption of every Balkan country plus Greece (in decreasing order of consumption): Romania, Greece, Bulgaria, Serbia, Croatia, Slovenia, Bosnia, Albania, North Macedonia, Kosovo, and Montenegro. Turkey consumes \(~285 \text{ TWh/year}\) so this one county (900 km2) consumes 80% of the electricity of a country that is about 900 times larger.
- This county and the county next store are unusual; in 2024 they were ranked as the largest concentration of Data Center capacity on Earth (Beijing was second with half as much).
9.2.1 A Single-Layer Neural Network
Neural networks are similar to other machine learning methods in that they are trying to estimate the true but unknown function \(f(X)\) that defines the relationships among variables (features).
- In the case of supervised learning, the relationship is between a set of input “features” (variables) \(X = X_1, \ldots, X_n\), the inputs, and one or more \(Y\) the (labeled) response or output.
The goal is to approximate the true but unknown function such that \(\hat{f}(X) \mapsto Y\) as accurately as possible.
One way to do this is through a neural network, which builds a model of this relationship by passing inputs through one or more layers of intermediate computations, ultimately producing a predicted output.
- Similar to boosted trees, the layers may have multiple nodes where each node is “weak”, but the combination of multiple nodes in the layer can generate “strong” (useful) results.
Deep Learning and Neural Nets have evolved in both computing and statistical domains and they combine aspects of computing, networks, statistics, and mathematics. Thus they tend to use different terms describing the same concepts, e.g., “features” are “predictors” are “inputs.”
- If you see different terms look at the underlying usage to help translate the concepts.
Figure 9.3 depicts a single layer neural network for a regression model with
- input nodes on the left, one for each predictor \(X_1, X_2, X_3\), and \(X_4\)
- a single “hidden” layer with multiple “units” (nodes), and
- an output layer on the right which generates the final prediction \(\hat{Y}\).
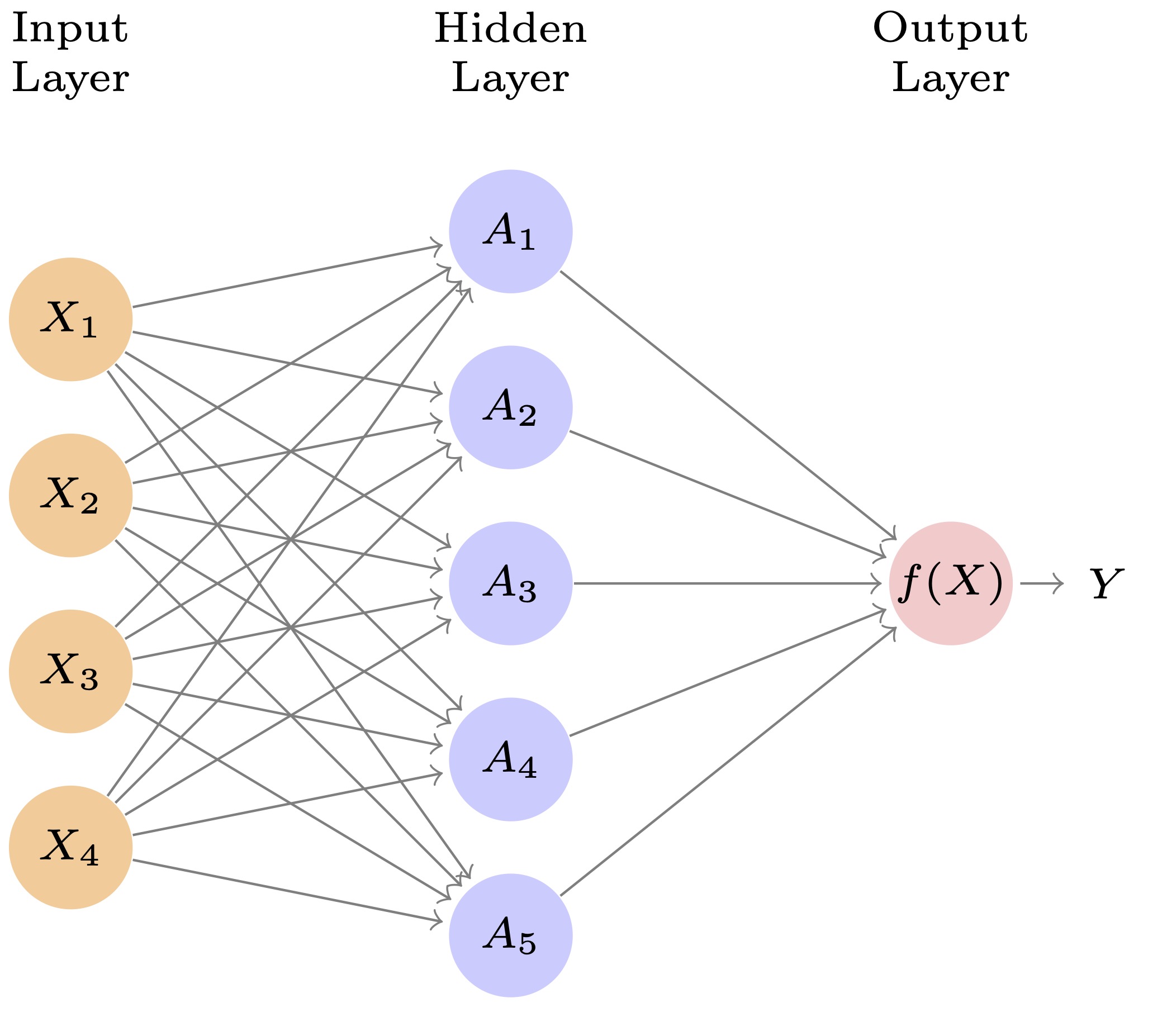
This network is taking information from four (predictor) inputs, \(X_1, X_2, X_3, X_4\) to generate an output layer \(\hat{f}(X)\) which predicts the response \(\hat{Y}\).
- The arrows from the inputs to the units (nodes) in the middle layer indicate each input is fed to a middle layer unit that will then combine all the inputs it receives.
- The number of units in a hidden layer, \(K\), is a tuning parameter (to be discussed later).
- Each unit applies a specific transformation to the inputs and sends its output to the final layer, which combines those \(K\) outputs into a final result/prediction.
The terms units, nodes, or “perceptrons” all refer to the individual elements of a network layer.
9.2.1.1 Weights and Biases - the Neural Network Analogs to Regression Coefficients
What distinguishes a neural network from other methods is the way the hidden layers make calculations on the inputs and the final layer then uses the outputs from the previous layer, as inputs to calculate a final prediction.
- The final layer has no visibility into or awareness of any of the previous layers; it is just seeing a set of input data to feed either a regression or a classification model.
To understand what happens inside a neural network, it helps to think in terms familiar from linear regression.
- In a basic linear regression, we use a weighted linear combination of inputs to compute a value \(Y\):
\[Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \dots + \beta_p X_p + \varepsilon \tag{9.1}\]
or, using the \(\sum\) symbol
\[Y = \beta_0 + \sum_i\beta_iX_i \tag{9.2}\]
To put Equation 9.1 and Equation 9.2 in the context of neural networks,
- The coefficients \(\beta_j\) are “weights” that indicate how important each feature is to predicting \(Y\).
- The intercept \(\beta_0\) acts like a constant shift, a baseline level when all \(X_j = 0\)..
Neural networks use similar ideas but in layers.
In the hidden layer, each unit has a twp step process:
- It computes a weighted sum of its inputs plus a bias, and then
- it applies a non-linear activation function \(g(\cdot)\):
Let \(A_k\) represent the output, \(h_k(X)\), of the \(k\)th unit in the hidden layer. Since this is a Neural Network equation we will use \(w_i\) instead of \(\beta_i\) for the “weights” and the bias term.
- \(A_k\) is calculated by computing the linear combination and then using the Activation function on it (right to left) in Equation 9.3.
\[A_k = h_k(X) = g(z) = g(w_0 + \sum_{i=1}^p w_iX_i) \tag{9.3}\]
where
- \(X_j\) is the \(j\)th input feature (for \(j = 1, \ldots, p\)),
- \(w_{kj}\) is the weight connecting input feature \(X_j\) to hidden unit \(k\),
- \(w_{k0}\) is the bias term for hidden unit \(k\),
- \(g(\cdot)\) is a nonlinear activation function (e.g., ReLU, sigmoid, tanh),
- \(z_k\) is just shorthand for the linear combination (before activation) for unit \(k\).
- \(h_k(X)\) just serves as a reminder that the output is really just a non-liner function of the inputs \(X\) for the node \(k\).
These \(w_{kj}\)’s and biases \(w_{k0}\) play the same role as \(\beta\)’s in regression: they determine how much influence each input has, but for each hidden unit individually.
- Analogy: You can think of the \(w_{kj}\) as being like regression coefficients, and the bias \(w_{k0}\) as the intercept, but for each mini-model inside the hidden layer.
The hidden unit output \(A_k\) is then passed to the output layer, which again uses its own weighted linear combination of the transformed inputs to create a prediction.
- Now in neural networks, it is customary to use \(\beta\)s again for the output layer since it a linear function, in a way representing the entire neural network as one huge function mimicking the true but unknown \(f(X)\).
\[f(X) = \beta_0 + \sum_{i=1}^K \beta_k A_k = \beta_0 + \sum_{i=1}^K \beta_k\, g\left(w_{k0} + \sum_{j=1}^p w_{kj}X_j\right) \tag{9.4}\]
where
- \(\beta_k\) is the output layer weight for hidden unit \(k\)’s \(A_k\) A,
- \(\beta_0\) is the output bias term.
So for this regression neural network:
- The hidden layer computes non-linear transformations of weighted combinations of inputs,
- The final layer is a linear model using the results of those transformations as input data.
9.2.2 Role of the Bias
Bias terms, both \(w_{k0}\) and \(\beta_0\), help shift the activation threshold of each unit or the mean of the output layer. If we left them out, every transformation would be forced to pass through the origin, which limits model flexibility.
In fact, you can think of the bias \(w_{k0}\) as setting a threshold (like in animal neurons): it helps determine whether a unit “activates” or not.
- For example, if you’re using a sigmoid activation, the bias controls the input value where the sigmoid flips from low to high.
9.2.3 Activation Functions
The activation function \(g(\cdot)\) introduces non-linearity which is crucial for neural networks to allow for flexible, non-linear, relationships and interactions among the data.
- If you removed all activation functions (or used a linear one), the network would collapse into a linear model, no more powerful than standard regression.
- Equation 9.4 would just be a linear combination of linear combinations from Equation 9.3 which is not new.
The user pre-selects the activation function with the goal of helping to clearly differentiate between signal and noise in the data.
An early choice was the sigmoid activation function
\[g(z) = \frac{e^z}{1+e^z} = \frac{1}{1+e^{-z}}. \tag{9.5}\]
- This is the same smooth function used with logistic regression.
- It has the nice property of transforming linear functions into probabilities from 0 to 1.
- Its sigmoid shape also helps highlight differences between signal and noise.
A more popular choice now is the ReLU (Rectified Linear Unit) activation function.
\[g(z) = (z)_+ = \cases{0 \quad \text{if } z<0 \\ z\quad \text{otherwise}} \tag{9.6}\]
- The ReLU calculations can be stored and computed faster than the sigmoid calculations.
- By design, it encourages “sparse” activation (many values are zero), which can help reduce overfitting and improve generalization.
Figure 9.4 shows the non-linear shapes of a sigmoid and a ReLU activation function.
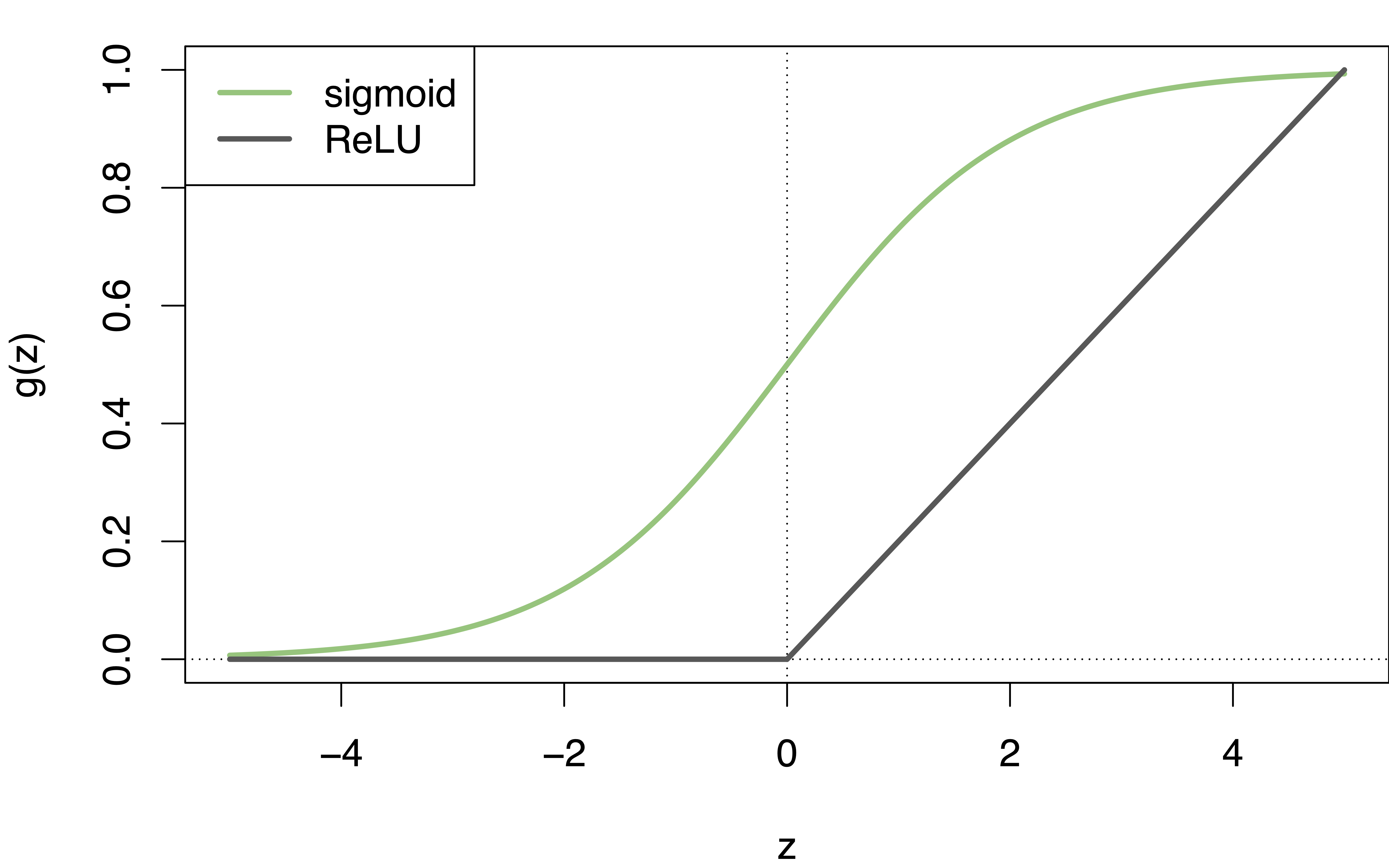
However, even though the \(g(z)\) are non-linear, the combinations in Equation 9.4 are still linear in their inputs.
- The final model results from calculating linear combinations at each hidden unit, doing a non-linear transformation of each, and then, doing a linear combination on the transformed results in the final layer.
- Since the final layer is still linear in its (transformed) inputs, we can use (for quantitative variables), the usual squared error loss as an objective function (loss function) to be minimized to calculate the \(\beta\)s, i.e..,
\[\sum_{i=1}^{n}(y_i - f(x_i))^2 \tag{9.7}\]
9.2.4 Learning the Weights and Biases
All of the weights \(w_{kj}\), biases \(w_{k0}\), and output weights \(\beta_k\) and \(\beta_0\) are “learned” from data.
Training typically involves defining a “loss function” for the output layer, e.g., squared error:
\[\sum_{i=1}^{n} \left( y_i - \hat{f}(x_i) \right)^2 \tag{9.8}\]
Then using gradient descent and backpropagation to adjust the weights and biases to minimize this loss.
9.2.5 Multi-layer Neural Networks
A single layer network can represent many possible \(\hat{f}(x)\).
Adding more hidden units in a layer and adding more layers allows for more possible transformations and provides more flexibility in the model.
- In general, adding more, smaller layers can make solutions easier to find than just adding more units in a single layer.
Neural Networks can support classification and regression models.
- The input and hidden layers have the same structure and operate the same.
- The difference is in the output layer.
- Classification has output nodes for each level or category to be predicted.
- Regression has a single output node which uses a regression model to estimate the response.
- Both use the outputs of the last hidden layer as inputs to the output layer’s calculations.
Figure 9.5 shows a multi-layer network for classification; in this example classifying digits (0-9) with a different number of units in each hidden layer.
- This network could use the MNIST Dataset of images of hand-written numbers as inputs to classify each image as a number.
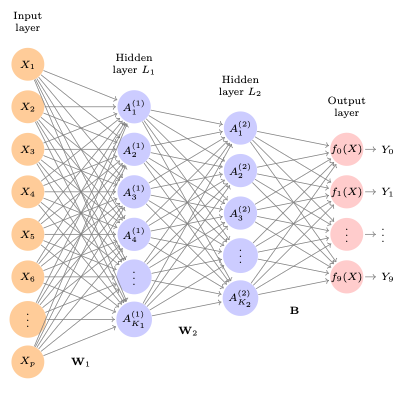
- It has two hidden layers L1 (256 units) and L2 (128 units).
- There are 10 nodes in the output layer since there are 10 possible levels to be classified
- Each is a dummy variable. In this case, the ten variables really represent a single qualitative variable so are dependent on each other.
Each of the activations in the units in the second layer is still a function of the original input \(X\), albeit a transformed version of it based on the activations in the first layer.
Adding more and more layers to the model builds a series of simple transformations into a complex model for the final result.
With more layers comes more notation.
- We can add a superscript to indicate the layer, e.g., \(A^{(1)}_{k}\).
- Consider all the parameters for each layer as a matrix. Thus we have \(W_1\), \(W_2\) and \(B\) as our three matrices of “weights” for the network.
There is no theorem that specifies the optimal number of hidden layers or nodes per layer for a given dataset.
- Architecture selection is a hyperparameter decision governed by the same bias–variance tradeoff that applies to choosing \(k\) in KNN or the degree of a polynomial.
- The workflow is: start with a reasonable architecture based on the heuristics in Table 9.1, fit the model, diagnose train vs. validation performance, then adjust the architecture if required.
Heuristics for Initial Architectures
| Design decision | Starting guidance | Rationale |
|---|---|---|
| Number of hidden layers | 1–2 for tabular data; add layers only when simpler model plateaus | Each layer learns more abstract features; most tabular problems do not need more than 2 dense layers |
| Nodes per layer | Between \(p\) and \(2p\) inputs; funnel shape (wider first layer, narrower second) | Enough capacity to learn patterns without diluting gradient signal; funnel compresses to relevant features |
| Total parameters | Aim for fewer than \(n/5\) free parameters as a rough ceiling | More parameters than this relative to \(n\) almost guarantees overfitting without heavy regularization |
| Output layer | 1 node (regression); \(M\) nodes (classification) | Fixed by the problem — not a tuning decision |
Other factors to consider:
- Data messiness / noise level: Noisier data favors shallower, more regularized networks. Deep networks fit noise aggressively and require stronger regularization to compensate.
- Number of input features \(p\): More inputs allow more nodes per layer before the parameter ceiling is reached.
- Nature of the inputs: Image, text, and sequence data benefit from specialized architectures (CNNs, RNNs, Transformers). Tabular/structured data generally does not.
- Computational budget: Deeper and wider networks cost more per epoch and typically require more epochs to converge.
- Symmetry-breaking at initialization: Always initialize weights randomly. Identical initial weights mean all nodes in a layer compute the same thing and the layer collapses to a single effective node.
The typical answer: start simple (1 hidden layer, \(K \approx p\) nodes), check the train/validation gap, and grow or regularize from there. The tuning workflow in Section 9.6 provides a systematic approach.
9.2.6 Coefficients to be Estimated
There are a lot of coefficients (weights) to be estimated in \(W_1\), \(W_2\), and \(B\).
There are 784 pixels in a \(28 \times 28\) pixel image. These are the inputs.
- Matrix \(W_1\) has \(785 \times 256 = 200,960\) elements. This is based on the 256 units and the 784 input values plus the intercept term (in NN called the “bias” term).
- Matrix \(W_2\) thus has \(128 \times 257 = 32,896\) (256 + bias term).
- Matrix \(B\) thus has \(10 \times 129 = 1,290\) elements. The 10 linear models for each level and the 128 outputs plus the bias term.
Together there are \(200,960 + 32,896 + 1,290 = 235,146\) coefficients (weights) to be estimated.
- This is 33 times more than just doing multinomial logistic regression.
- With a training set of only 60,000 images, there is a lot of opportunity for overfitting.
To avoid overfitting, some regularization is needed. Options include Ridge, Lasso, or neural-network specific methods such as dropout regularization.
9.2.7 Softmax Activation Function
Since the outputs are dependent, they represent the probabilities that a given input corresponds to each possible image class and must sum to 1, this classification model will use the softmax activation function for the output layer.
\[f_m(X) = Pr(Y=m | X) = \frac{e^{Z_m}}{\sum_{l=0}^{9}e^{Z_l}} \tag{9.9}\]
Equation 9.9 is a generalization of the logistic function from binary logistics regression to multiple levels needed in multinomial logistic regression.
- During each forward pass, the model assigns probabilities to each possible output. This is the result of the softmax “soft” prediction instead of choosing just the one value with the highest probability.
- These output probabilities are a vector that sums to 1. One class may have the highest probability, but most probabilities are typically nonzero.
- When training starts, probabilities are fairly evenly distributed given the random assignment of initials weights and biases. As training proceeds through multiple epochs, the model gradually shifts increases the probability for the “correct” output value and decreases other probabilities.
- A key advantage of softmax is that Equation 9.9 is differentiable, which allows us to compute gradients to feed backpropagation. In contrast, the
max()function is not differentiable and therefore not suitable during training.
After training is complete, when we no longer need gradients, we can apply a max() operation to the softmax output vector to make a final “hard” prediction, selecting the class (dummy variable) with the highest predicted probability as our prediction.
9.2.8 Minimization by Cross-Entropy
Since the response variable has multiple categories, we use a loss function called the negative multinomial log-likelihood, more commonly known as cross-entropy loss.
- During training, the neural network adjusts its weights and biases to minimize this loss, thereby increasing the predicted probability assigned to the correct class.
When class labels are represented directly as integer indices (e.g., \(y_i \in \{0, 1, \ldots, 9\}\)), the cross-entropy loss, for all \(n\) inputs, takes the form:
\[ R(\theta) = -\sum_{i=1}^{n} \log(f_{y_i}(x_i)) \tag{9.10}\]
- Here, \(y_i\) is the index of the true class label for the \(i^\text{th}\) input.
- \(f_{y_i}(x_i)\) is the predicted probability (from the softmax output in Equation 9.9) corresponding to that true class.
This form is computationally efficient and is the one typically used in practical implementations.
Cross-entropy is useful in conjunction with Softmax as it is an efficient way to penalize the model more heavily when it assigns a low probability to the true class.
9.3 Fitting a Neural Network
Fitting a neural network is complex due to the necessarily non-linear activation functions.
Deep learning and neural networks is an active area of research across many communities. You will see many different terms often describing the same concept or approach.
- You will also see many articles or references describing the latest approaches.
- What follows is not exhaustive by any means. It is designed to provide familiarity with some approaches to provide a basic understanding.
There are many tuning parameters (hyper-parameters) in neural networks and the selection for a given set of data is still very much an art more than a science.
While the objective function in Equation 9.8 looks familiar, minimizing it over the activation functions is non-linear.
Neural Networks use non-linear activation functions so their objective functions are non-convex and have multiple local optima in addition to a global optimum.
- Instead of trying to find the “best” model at the one global optimum, potentially out of millions, we seek to find a useful model at a “reasonable” local minima.
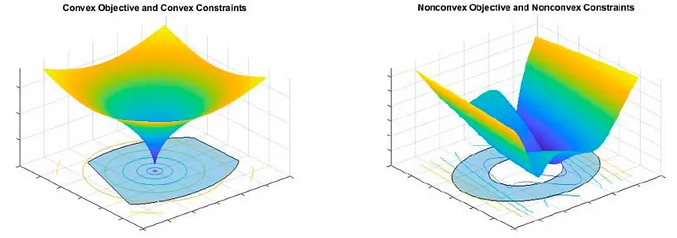
Two strategies help find better local optima and reduce the chance of overfitting.
- Slow Learning: slow learning uses small steps to reduce the chance of overfitting. The algorithm stops when overfitting is detected.
- Regularization: Imposing penalties on the parameters such as with Ridge and LASSO regression.
Assume all the parameters (coefficients) are in a single vector \(\theta\).
We can define the loss function as in Equation 9.11 and we want find the \(\theta\)s (our weights and biases) that minimize it.
\[R(\theta) = \frac{1}{2}\sum_{i=1}^n(y_i - f_\theta(x_i))^2. \tag{9.11}\]
A general optimization algorithm could look like this:
- Initialize: Make an initial guess for all the parameters, \(\theta^0\), and set \(t = 0\).
- Update step: Find a vector \(\delta\) that represents a small change in \(\theta\) such that the new parameters \(\theta^{t+1} = \theta^t + \delta\) reduce the value of \(R(\theta^t)\).
- Check improvement: If \(R(\theta^{t+1}) < R(\theta^t)\), set \(t = t + 1\) and return to step 2.
- Stop condition: If no meaningful reduction is achieved, Stop. The algorithm has likely reached a local minimum of the loss function.
How do we find a good \(\delta?\)
9.3.1 Gradient Descent and Backpropagation
Finding \(\delta\) is the core challenge in training neural networks.
- We want to move \(\theta\) in the direction that reduces the error most efficiently.
- That direction is given by the negative of the gradient of the objective function: \(\delta = -\eta \cdot \nabla_\theta R(\theta)\).
Think of the gradient as a slope of a line but in multiple dimensions, the default calculation points in the direction of steepest increase in the loss.
So, to minimize the loss, we move in the opposite direction of the gradient, the negative gradient.
Imagine you are on a hill and want to get to the valley below (reach the lowest point (the minimum loss)).
- The gradient is the direction going up the hill is steepest.
- If you step in the opposite direction of the gradient, you’re going downhill and finding the better set of weights and bias that will give you a lower error.
- The learning rate is how big of a step you take before you calculate the next gradient.
Each weight and bias has its own gradient and we update them individually using a method called gradient descent.
- The gradient, \(\nabla_\theta R(\theta)\), shows how the error would change by updating (increasing or decreasing) each weight/bias.
- The learning rate, \(\eta\) (eta) controls how big a step we take in the opposite direction of the gradient.
- The minus sign ensures we move in the direction that reduces the error, not increases it.
- You may see the term the “gradient vector” for a node which is shorthand for the set of all the individual gradient entries for each weight/bias parameter.
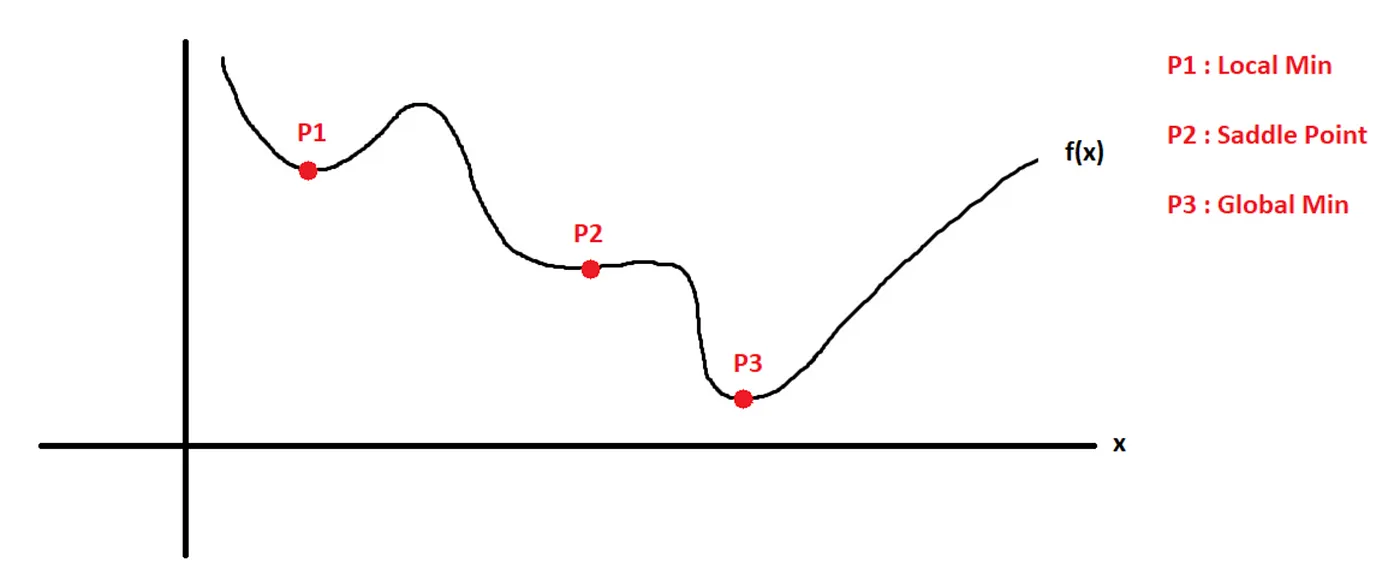
Figure 9.7 provides one view of how gradient descent can lead to different local optima with slightly different starting points.
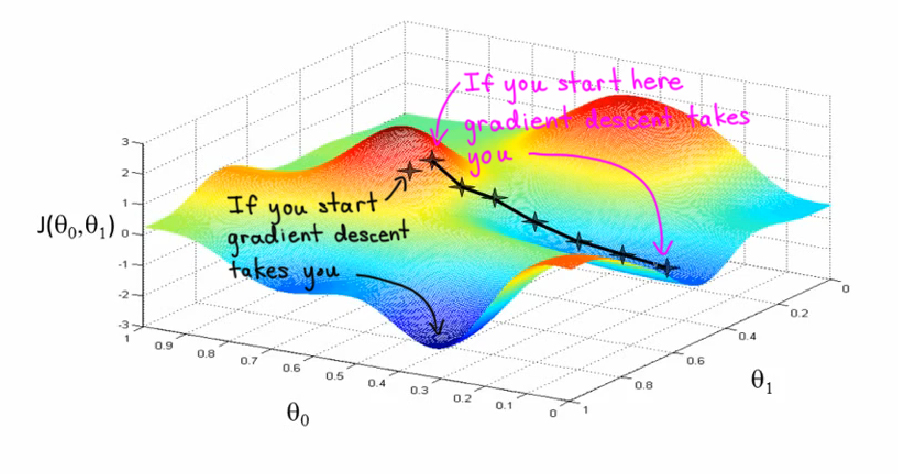
9.3.1.1 Backpropagation: An Intuitive Analogy
Backpropagation is how a neural network learns from its mistakes. You can think of it like how a child learns to shoot a basketball:
- Take a shot: The child throws the ball. This is the network making a prediction.
- See the result: The child sees if the shot missed or scored. This is the model calculating the error.
- Figure out what went wrong: Did the shot go too far? Was the angle off? This is feedback.
- Adjust next time: The child throws again, tweaking their motion. This is weight adjustment using backpropagation.
How It Works in a Neural Network
- The prediction is the forward pass where the model computes \(f_\theta(x)\).
- The error is the difference between predicted and actual values: \(y_i - f_\theta(x_i)\).
- Backpropagation takes this final error and sends it backward through the network, using the chain rule as it goes layer by layer, to calculate the gradient of the loss with respect to every weight/bias parameter.
In other words:
- Starting with the residual (final error), we compute how much each parameter contributed to that error and how it should change.
- This is done layer-by-layer from right to left (going backwards, output to input), updating weights across each layer.
9.3.1.2 Why It Matters
Backpropagation makes training deep models computationally feasible. It allows the model to:
- Efficiently compute \(\nabla_\theta R(\theta)\) for all parameters, even in deep networks.
- Update its parameters using a simple rule: \(\theta^{t+1} = \theta^t - \eta \cdot \nabla_\theta R(\theta^t)\)
- Learn from experience, gradually reducing error as it sees more examples.
9.3.2 Epochs
We know how to do three things:
- A Forward Pass: Use the initial inputs to compute the outputs for each unit in each layer (using the estimated weights and activation functions) to get to an output layer where the parameters (\(\beta\)s) are estimated (based on optimizing a loss function) to produce a prediction \(\hat{y}_i\) for each observation \(x_i\).
- Calculate the residuals \((\hat{y}_i - y_i)\).
- A Backwards Pass: Use the gradient of the loss function to allocate the residuals as a \(\delta\) to update each of the weights in the network thorough backpropagation.
We will repeat those steps multiple times in training the network.
An Epoch is defined as one complete forward pass and a complete backward pass (steps 1-3) through the network where every observation in the training data set contributes to the update.
- The number of epochs to use is a tuning parameter when building the model.
- There are trade offs of time and accuracy as well preventing overfitting.
9.3.3 Options for Epochs
With so many calculations to be made, there are different approaches to how to use the training data in each epoch.
- Massive data sets can require many computations and significant memory to hold all the data at once.
- Research continues into multiple options for improving the speed and reducing the memory requirements for neural networks.
Each approach has trade offs between how long it takes to complete an epoch, how fast or slow to get to convergence, how smoothly to get to convergence, how to reduce bias or multicollinearity, and how much memory is required.
There are three popular approaches for how much data to include in each forward/backward pass through the network. see Batch, Mini Batch & Stochastic Gradient Descent.
- Batch Gradient Descent
- All the observations are used at once, in a single batch or iteration.
- When data space is “well-behaved”, it can provide for a smooth convergence across multiple epochs.
- It does require all the data fit into memory at once.
- Stochastic Gradient Descent is the other extreme where only one observation at a time is fed into the model.
- Thus there are \(n\) batches and each batch is processed in an iteration.
- Much less data has to be computed each time and much less has to fit into memory.
- The convergence can be less smooth as observations can vary widely.
- Mini-Batch Gradient Descent
- This is in between the others where a fraction of the data is used for each batch.
- If there are \(m\) batches, each batch uses \(n/m\) observations with the last batch using whatever remains after the \(m-1\)st batch.
- There are different methods for whether to update the \(\delta\)s after each mini-batch (do a backwards pass) or just store the residuals from a forward pass to update \(\delta\)s after all mini-batches have been run and you have \(n\) residuals.
- There is some evidence that small batches (32) may be less smooth but converge more quickly and be more robust in prediction.
- Hybrid Approaches
- This is my term for the variety of methods that combine aspects of multiple approaches.
- One such method is to select the observations for each iteration at random (with/without replacement.
- This would mean that perhaps not all \(n\) observations made it into each epoch.
- Another method is to randomly shuffle all the input data at each epoch so different data goes into different batches for each epoch.
Some use the term Stochastic Gradient Descent (SGD) as shorthand to refer to all the above approaches for selecting the data to be used in an iteration.
9.3.4 Using Matrix Algebra to Execute an Epoch
Updating one weight at a time in a loop would be mathematically correct but computationally prohibitive!
- A network with even a few hundred nodes has thousands of parameters, and doing so for thousands of epochs over millions of observations is impractical.
- Instead, all gradients are computed and all parameters updated simultaneously pass using matrix algebra, which modern hardware (GPUs) executes in parallel.
The key insight is the forward and backward passes across all \(n\) observations can be written as matrix operations.
Forward Pass: We start with two matrices
- Stack all input observations into a matrix \(\mathbf{X}\), and then,
- Stack all the Layer 1 weights and biases into a matrix \(\mathbf{W}^{(1)}\).
- Rather than computing the values for one observation at a time, all the observations are stacked into matrices and processed simultaneously.
- The entire Layer 1 pre-activation calculation, for all nodes and all observations at once, is then a single matrix multiplication.
- The Activation function is another Matrix operations and the resulting matrix is passed to the next layer and so on to the Output layer.
Loss Gradient:
- Once the output layer is calculated, the gradient of the total loss with respect to the output weight vector is the sum of per-observation gradients stacked into a matrix over all \(n\) observations.
Back Propagation:
- The updates for each node in each layer can be computed as a matrix as well.
- With all gradient matrices computed from the current (pre-update) weights, the update rule is applied to all parameters at once:
- This is what makes the update truly simultaneous: no layer sees partially-updated parameters from another layer during the backward pass.
The process repeats for each epoch so over many epochs, the weight matrices converge to values that minimize the loss on the training data and, ideally, generalize well to new data.
The matrix multiplications are computationally cheap for small model and small data sets.
- At real-world scale, with billions of parameters, they are among the most demanding computations humans have ever designed.
- Understanding why GPUs handle them efficiently requires a short detour into the history of video games.
A video game must render a three-dimensional virtual world onto a flat screen 60 or more times per second.
- Every surface in that world is represented as a mesh of triangles.
- Moving each triangle from 3-D world-space to 2-D screen-space requires multiplying its \((x, y, z)\) coordinates by a series of transformation matrices (rotation, scaling, perspective projection).
- A single frame of a modern game may involve tens of millions of these matrix operations, all of which must finish within ~16 milliseconds.
Chip designers in the 1990s–2000s (NVIDIA, ATI/AMD) solved this by building special processors with thousands of small, simple arithmetic cores that execute matrix multiplications in parallel: the Graphics Processing Unit (GPU).

- A CPU has 8–64 large, general-purpose cores optimized for sequential logic; a GPU has 3,000–16,000 small cores optimized for doing the same arithmetic operation on thousands of numbers simultaneously.
When researchers in the early 2010s (most famously AlexNet, 2012) began training neural networks on GPUs, they discovered that the forward and backward passes are structurally identical to the matrix operations in game rendering: large matrix multiplications that are embarrassingly parallel.
- Training time that took weeks on CPUs dropped to days or hours on GPUs.
- The deep learning revolution that followed was in large part a consequence of commodity gaming hardware.
9.3.4.1 Model Scale in 2025
The table below places compares leading models across several dimensions.
- Every model below is structurally identical to the examples; the same forward pass, the same chain rule, the same update rule, just with more layers, more nodes, and far more parameters.
| Scale | Example models | Parameters | Training hardware | Training time |
|---|---|---|---|---|
| Toy | A classroom example | 61 | Spreadsheet / CPU | Milliseconds |
| Small | LeNet, shallow MLP | 100K–1M | Laptop CPU | Minutes |
| Medium | ResNet-50, BERT-base | 25M–110M | 1–4 GPUs | Hours–days |
| Large | GPT-2, ViT-L | 1.5B–300M | 8–64 GPUs | Days–weeks |
| Frontier | GPT-4 (~1.8T), Llama 3 405B | 100B–2T | 1,000s of GPUs | Months |
A single training step of GPT-3 (175 billion parameters) requires approximately \(3.14 \times 10^{23}\) floating-point operations (Brown et al. 2020).
- At 125 TFLOPS (fp16) per NVIDIA A100 GPU, that would take one GPU roughly \(8 \times 10^7\) seconds or about 2.5 years.
- OpenAI trained it on ~10,000 GPUs in parallel over several months.
The architecture in our examples scales directly to frontier models.
- GPT-4 is, at its core, a very deep network of matrix multiplications and non-linear activations, the same operations as above, repeated \(\sim 10^{11}\) times per forward pass.
For problems at industry or research scale, compute cost is a primary design constraint; a major reason GPUs and matrix algebra are fundamental to large neural networks.
- It’s also one reason why transfer learning (Section 9.10) and fine-tuning are so important: they let you build on a frontier model’s pre-learned weights rather than incurring the cost of training from scratch.
9.3.5 Optimization Algorithms
The discussion above covers how much data to use per update step.
- A separate question is how to move in the direction of the gradient, the choice of optimization algorithm (optimizer).
- Older models use standard gradient descent; in practice, almost all modern neural network training uses an adaptive optimizer that adjusts the effective learning rate per parameter automatically.
Adaptive optimizers maintain running estimates of past gradients, allowing parameters that receive small or infrequent gradients to take larger steps and parameters with large consistent gradients to take smaller steps.
Table 9.3 lists the main choices:
| Optimizer | Key idea | When to prefer |
|---|---|---|
| SGD | Fixed \(\eta\), pure gradient step | Theoretical work; convex problems; CNNs with careful tuning |
| SGD + Momentum | Accumulates a velocity vector across steps; smooths oscillations | Image classification with CNNs |
| RMSProp | Divides \(\eta\) by a running average of squared gradients; adapts per parameter | Recurrent networks; was Keras default historically |
| Adam | Combines momentum (first moment) + RMSProp (second moment); bias-corrected | Default for most tasks — tabular, NLP, vision |
| AdamW | Adam with decoupled weight decay (L2 penalty applied separately from gradient) | Fine-tuning pre-trained transformer models |
Adam (Kingma and Ba 2017) is the practical default for almost all deep learning work as of 2025
- The learning rate \(\eta\) (Table 9.9) still requires tuning as Adam’s adaptivity reduces sensitivity to the initial choice but does not eliminate it.
- Momentum (first moment): Momentum keeps a running average of past gradients so it “remembers” which direction the parameters have been moving and keeps pushing that way, smoothing out noisy updates.
- In statistics, the mean of a distribution is called the first moment, so this running average of gradients is the “first moment estimate.”
- RMSProp (second moment): RMSProp keeps a running average of past squared gradients. This measures how large the gradients have been recently, and uses it to scale the learning rate down for parameters that get large gradients and up for parameters that get small ones.
- The mean of squared values is the second moment, hence “second moment estimate.”
- Bias-corrected: Early in training, both running averages start at zero, which biases them toward zero before they’ve had enough updates to reflect the true gradient history.
- Adam applies a correction factor that compensates for this initialization bias, making the early updates more reliable.
9.3.6 When to Stop Training
Training is an iterative loop.
- After every epoch the parameters improve, but running too many epochs leads to overfitting where the model “memorizes” the training data and performs poorly on new observations.
- Two families of stopping criteria control this.
9.3.6.1 Loss-Based Convergence Threshold
The simplest approach monitors how much the training loss changes from one epoch to the next:
- Training stops when \(\Delta R^{(t)}\) falls below a pre-specified threshold \(\epsilon\) for \(p\) consecutive epochs:
- Both \(\epsilon\) and \(p\) are hyperparameters set before training begins.
9.3.6.2 Early Stopping on Validation Loss
A more careful approach splits training data into a training set and a held-out validation set (typically 80/20 or 70/30). After each epoch, the loss is evaluated on both.
- Training stops when validation loss stops improving for \(p\) consecutive epochs, even if training loss is still declining.
- The weights from the epoch with the lowest validation loss are restored as the final model.
Early stopping acts as an implicit form of regularization: it prevents the model from fitting noise in the training data by halting before the validation curve turns upward.
9.3.6.3 The Bias–Variance Trade Off in Training
The goal of stopping criteria is to locate and halt at the sweet spot (Table 9.4).
| Training phase | Training loss | Validation loss | Interpretation |
|---|---|---|---|
| Early epochs | High | High | Underfitting: model has not learned enough (high bias) |
| Middle epochs | Decreasing | Decreasing | Sweet spot: generalizing well |
| Late epochs | Very low | Increasing | Overfitting: memorizing training data (high variance) |
- It is common to plot the improvement in model performance against the number of epochs to see if there is a good stopping point.
- If the improvement is too rough or noisy, shrinking the learning rate can smooth things out.
9.4 Evaluating the Model
During development, the model is evaluated on a validation set of observations held back from training.
- At this stage the goal is not to report final performance but to compare candidate architectures and tuning choices, e.g., the number of layers, nodes, activation functions, regularization, learning rate, batch size, and stopping point.
- The goal is to select the best configuration.
- Because every decision made at this stage is informed by the validation set, it cannot later serve as an unbiased estimate of real-world performance; that role is reserved for the test set.
9.4.1 Regression Metrics
The validation set predictions \(\hat{y}_i\) are compared to the true values \(y_i\) using one or metrics such as from Table 9.5:
| Metric | Formula | Interpretation |
|---|---|---|
| MSE | \(\frac{1}{n_{\text{val}}} \sum (y_i - \hat{y}_i)^2\) | Average (Mean) squared error; in units of \(y^2\) |
| RMSE | \(\sqrt{\text{MSE}}\) | Average error in the original units of \(y\), \(\sqrt{\text{MSE}}\) |
| MAE | \(\frac{1}{n_{\text{val}}} \sum |y_i - \hat{y}_i|\) | Mean Absolute Error is less sensitive to large outliers than RMSE |
| \(R^2\) | \(1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2}\) | Proportion of variance explained; 1 = perfect, 0 = no better than the mean |
9.4.1.1 Choosing a Regression Metric for Model Comparison
When comparing architectures on the validation set, the chosen metric should reflect what kinds of errors matter most in the application, and that same metric should be used consistently across all candidate models so comparisons are meaningful.
- RMSE is the most common default for comparing models.
- Because squaring penalizes large errors more heavily, it is the right choice when large prediction errors are disproportionately costly.
- As an example, when forecasting energy demand, a large miss may trigger an outage.
- MAE treats all errors proportionally to their size, making it more appropriate when the cost of errors scales roughly linearly and when outliers in \(y\) should not dominate the comparison.
- As an example, when predicting delivery times, occasional extreme values should not distort the overall picture.
- \(R^2\) is useful for communicating how much variability the model explains relative to a simple mean baseline, but it should be used alongside RMSE or MAE rather than alone.
- A high \(R^2\) does not guarantee errors are small enough to be practically useful.
- MSE is most useful as an intermediate quantity for computation or programmatic comparison rather than as a reported metric, since its units are squared.
The key diagnostic during validation: compare \(\text{RMSE}_{\text{train}}\) to \(\text{RMSE}_{\text{val}}\) across candidate models.
- A large and growing gap as model complexity increases is the signature of overfitting, and signals that regularization, reduced capacity, or more data are needed before proceeding.
9.4.2 Classification Metrics
With softmax probabilities \(\hat{P}(m | x_i)\) and a 0.5 threshold for the predicted class, there are also a variety of possible metrics as in Table 9.6:
| Metric | Interpretation |
|---|---|
| Accuracy | Overall fraction correct; can be misleading if classes are imbalanced |
| Cross-entropy loss | Penalizes confident wrong predictions most heavily |
| Confusion matrix | Counts of True Positive / False Positive / True Negative / False Negative |
| Precision | Of all predicted positives, what fraction are correct |
| Recall (Sensitivity) | Of all true positives, what fraction did the model catch |
| F1-score | Harmonic mean of Precision and Recall; balances both |
| AUC-ROC | Threshold-independent ranking ability; 0.5 = random, 1.0 = perfect |
9.4.2.1 Choosing a Classification Metric for Model Comparison
The right metric for comparing candidate models depends on class balance and, critically, on the relative cost of different types of errors in the application.
- Selecting this metric before comparing architectures, rather than after seeing results, avoids the temptation to switch metrics to favor a preferred model.
In binary classification, two kinds of mistakes are possible:
- A Type I error (false positive): the model predicts the positive class when the true class is negative.
- A Type II error (false negative): the model predicts the negative class when the true class is positive.
These errors rarely carry equal consequences, and the choice of comparison metric should reflect which error is more costly in the application at hand.
The examples in Table 9.7 provide some suggestions.
| Scenario | Costly error | Preferred metric | Threshold tendency |
|---|---|---|---|
| Disease screening | False negative (missed case) | Recall, AUC-ROC | Lower threshold |
| Fraud / anomaly detection | False negative (missed event) | Recall, AUC-ROC | Lower threshold |
| Spam filtering | False positive (lost legitimate email) | Precision | Higher threshold |
| Balanced risk (equal costs) | Either | F1-score, Accuracy | 0.5 default |
| Imbalanced classes | Either | AUC-ROC, F1-score | Tune on validation set |
Accuracy is often the first metric reported but can be deeply misleading when classes are imbalanced.
- A model that predicts “no fraud” for every transaction will achieve 99.9% accuracy on a dataset where fraud occurs in 0.1% of cases, while catching nothing of interest.
- In such settings, Recall, Precision, F1, or AUC-ROC give a much clearer picture of which architecture is actually performing better.
AUC-ROC evaluates model performance across all possible classification thresholds rather than committing to a single cutoff such as \(0.5\).
- This makes it particularly useful when comparing architectures on the validation set, since it is not sensitive to the choice of threshold.
- A high AUC-ROC indicates the model ranks positives above negatives reliably; once a final architecture is chosen, the threshold can be set to reflect the application’s specific cost profile.
9.4.2.2 Adjusting the Classification Threshold
The default 0.5 threshold treats false positives and false negatives as equally undesirable.
When the risk profile is asymmetric, the threshold should be moved, and the validation set is the appropriate place to explore this before any final decisions are made:
Lowering the threshold (e.g., to 0.3) flags more observations as positive, increasing Recall at the cost of more false positives.
- This is appropriate when missing a true positive carries high consequences, for example, in anomaly detection or medical screening.
Raising the threshold (e.g., to 0.7) increases Precision by only predicting positive when the model is highly confident, at the cost of missing more true positives.
- This is appropriate when false alarms are costly, for example, in a content moderation system where incorrectly flagging legitimate content damages user trust.
9.4.3 Diagnosing Train vs. Validation Performance
Table 9.8 maps the observable patterns across candidate models to a diagnosis and a primary remedy.
| Pattern observed | Diagnosis | Primary remedy |
|---|---|---|
| Both train and val loss are high | Underfitting (high bias) | More capacity, less regularization |
| Train loss low, val loss much higher | Overfitting (high variance) | Regularize, reduce capacity, add data |
| Train and val loss both low and close | Good fit | Minor fine-tuning only |
| Val loss erratic across architectures | Insufficient validation set size | Larger validation set or \(k\)-fold CV |
9.4.4 From Validation to Final Reporting
Once a final architecture and tuning configuration have been selected using the validation set, the model is evaluated a single time on the held-out test set.
- The same metric used to compare models during validation should be used to report final performance.
- Switching metrics at this stage would make it impossible to know whether the final result is consistent with what was optimized during development.
- This final test set result is the number that represents how the model is expected to perform on genuinely new data.
Since the number of coefficients to be estimated (the \(w\)s and \(\beta\)s) can often be greater than the number of observations, using a regularization method can reduce the risk of overfitting.
9.5 Regularization of Neural Networks
9.5.1 Regularization Methods for Optimization.
One can use LASSO (L1) and Ridge (L2) regularization in neural networks by adding a penalty term to the overall loss function during training.
- The forward pass itself is unchanged: hidden layers compute activations normally.
- After the network produces predictions and the data loss is computed, the regularization penalty is added based on the size of the weights in the hidden and/or output layers.
- During backpropagation, the gradients from this penalty are added directly to the ordinary prediction-error gradients for each penalized weight matrix.
- In effect, training simultaneously tries to improve predictive accuracy while also discouraging overly large weights.
Key distinctions:
- Ridge (L2) regularization shrinks weights smoothly toward zero and is commonly implemented as “weight decay.”
- LASSO (L1) regularization encourages sparsity by pushing some weights exactly to zero.
- The penalty is not inserted into the hidden-layer activation calculations themselves.
- The regularization effect enters during optimization and parameter updates, not as part of the hidden-layer forward computations.
Modern deep learning systems most commonly use L2 regularization, often together with techniques like dropout and early stopping.
9.5.2 Dropout Learning
Dropout Learning is a regularization method (similar to Random Forests) where for each iteration in an epoch, we randomly select a fraction of the nodes, \(\phi\), (phi) to “drop out” of the calculation.
- The remaining weights are scaled by a factor of \(1/(1-\phi)\) to compensate for the missing units.
- In practice, dropout is achieved by randomly setting the activations for the “dropped out” units to zero.
- One can also insert a “dropout layer” between the input nodes and the first hidden layer.
Dropout Learning reduces the opportunity for nodes to become “too specialized” as other nodes have to make up for the residuals when they are dropped out. This tends to improve performance in prediction.
There are multiple suggestions to help with adjusting the drop out rate (Dropout Regularization in Deep Learning Models with Keras). These include:
- Use a small dropout value of 20%-50% of neurons, with 20% providing a good starting point. A probability too low has minimal effect, and a value too high results in under-learning by the network.
- Use a larger network. You are likely to get better performance when Dropout is used on a larger network, giving the model more of an opportunity to learn independent representations.
- Use Dropout on incoming (visible) as well as hidden units. Application of Dropout at each layer of the network has shown good results.
9.5.3 Batch Normalization
Batch normalization (batch norm) is now a standard technique in almost every modern neural network.
As networks get deeper, a subtle problem emerges: the distribution of pre-activations entering each layer shifts as the weights in earlier layers update, forcing later layers to constantly adapt to a moving target.
- This shift phenomena slows training and destabilizes convergence.
- It is sometimes called internal covariate shift.
Batch normalization addresses this problem by standardizing the pre-activations at each layer before passing them through the activation function, keeping the inputs to each layer in a stable, well-behaved range throughout training.
- It is applied between the linear combination \(z^{(l)}_{k,i}\) and the activation function \(g(\cdot)\) at each hidden layer.
The idea is straightforward: before applying \(g(\cdot)\), standardize the pre-activation values to have mean 0 and variance 1, then allow the network to learn a rescaling.
Why it helps:
- Stabilizes training: keeps pre-activations near zero at the start of training, where ReLU is active and gradients flow freely.
- Large pre-activations are the main cause of saturated neurons and vanishing gradients.
- Allows higher learning rates: because activations are kept in a well-behaved range, larger \(\eta\) steps are safe, speeding convergence.
- Acts as mild regularization: the batch-level statistics introduce noise that has a similar effect to dropout, slightly reducing overfitting.
- Reduces sensitivity to initialization: poor weight initialization matters less when batch norm re-centers activations every forward pass.
In Keras/TensorFlow, batch norm is added as a layer: layer_batch_normalization() inserted after layer_dense() and before the activation.
- It is typically used with ReLU hidden layers and is less common at the output layer.
9.6 Tuning Neural Networks
Tuning a neural network means systematically searching for the combination of hyperparameters that minimizes validation loss.
- Unlike the weights and biases, which are learned from data during training, hyperparameters must be set by the analyst before training begins.
9.6.1 Hyperparameter Inventory
Table 9.9 provides an inventory of tunable hyperparameters, what each controls, and the consequences of setting it too small or too large.
| Hyperparameter | What it controls | Too small / few | Too large / many |
|---|---|---|---|
| Number of hidden layers | Model depth | Underfits complex patterns | Overfits; harder to train |
| Nodes per layer (\(K_1, K_2\)) | Model width | Underfits | Overfits; slower |
| Learning rate \(\eta\) (or \(\rho\)) | Step size per gradient update | Very slow convergence | Oscillates or diverges |
| Batch size | Observations per gradient step | Noisy gradients (SGD) | Smooth but slow; memory-heavy |
| Epochs / patience \(p\) | How long to train | Underfits | Overfits (without early stopping) |
| Dropout rate \(\phi\) | Fraction of nodes zeroed per pass | No regularization effect | Too much information destroyed |
| L2 penalty \(\lambda\) | Weight shrinkage | No regularization | Underfits, all weights near zero |
| Activation function | Non-linearity at hidden nodes | Linear, collapses to regression | Depends on task and data |
See Tip 9.1 for guidance on choosing the initial depth and width before tuning begins.
9.6.2 Addressing Underfitting (High Bias)
If both training and test loss are too high, the model lacks the capacity to capture the true pattern:
- Increase depth or width: add a hidden layer or increase \(K_1\), \(K_2\)
- Reduce regularization: lower \(\lambda\) or reduce dropout rate \(\phi\)
- Train longer: increase max epochs or lower the \(\epsilon\) threshold.
- Use a more expressive activation: switch from linear to ReLU or sigmoid in hidden layers
- Increase learning rate slightly if training is stagnating in early epochs
9.6.3 Addressing Overfitting (High Variance)
If training loss is low but test loss is substantially higher, the model has memorized training noise.
- The remedies draw directly on the regularization tools in Section 9.5:
- Dropout: randomly zero activations each epoch; forces redundant representations. Start with \(\phi = 0.2\)–\(0.5\).
- L2 weight penalty: adds \(\lambda\sum_\theta \theta^2\) to the loss; shrinks large weights toward zero. Tune \(\lambda\) per layer if needed.
- Early stopping: freeze parameters at the epoch with lowest validation loss.
- Reduce model capacity: fewer nodes or fewer layers
- Collect more training data: the most reliable remedy when feasible
9.6.4 Tuning Strategy
Table 9.10 summarizes the main search approaches, from manual exploration to automated methods.
| Method | Description | When to use |
|---|---|---|
| Manual search | Adjust one hyperparameter at a time guided by train/val loss curves | Initial exploration; builds intuition |
| Grid search | Evaluate all combinations of a fixed set of candidate values | Small hyperparameter spaces |
| Random search | Sample hyperparameter combinations randomly | Larger spaces; often outperforms grid for the same compute budget |
| Learning curves | Plot train and val loss vs. epochs or training set size | Diagnose bias vs. variance before committing to a search |
The gap between the training and validation loss curves at any epoch is the direct visual measure of overfitting.
- The goal of tuning is to shrink that gap while keeping both curves low.
9.7 Using the Trained Network Model
Once training is complete and a final model is selected through performance evaluation and tuning, the network weights are frozen and the model is ready for use on new data.
Only the forward pass is needed for inference.
- Inputs are propagated through the network applying the learned weights and activation functions until the output layer produces a predicted value or class probability.
- No gradient calculations occur, so scoring new observations is fast and memory-efficient regardless of the batch strategy used during training.
9.8 Exercise 09: Experimenting with Google Colab
Google Colab (https://colab.research.google.com/ ) provides a convenient browser-based environment for experimenting with neural networks and modern AI workflows without requiring you to install Python, TensorFlow, or other machine learning libraries on your personal computers.
- Colab notebooks run entirely in the browser and provide access to preconfigured Python environments with scientific computing and deep learning tools already installed.
- This allows one to focus on the conceptual aspects of neural networks such as forward passes, backpropagation, optimization, and hyperparameter tuning, rather than spending time debugging software installations or configuring local environments.
You can download a Colab Jupyter notebook at https://github.com/AU-datascience/data/blob/main/427-627/colab_nn_examples.ipynb and upload it into Google Colab to use as an interactive “playground” for experimenting with neural networks on small datasets.
- The notebook is in written in Python but you can experiment by changing the cells that define the hyperparameters for the networks included as examples.
- You can can modify network architectures, activation functions, learning rates, and training parameters and immediately observe how those changes affect model performance.
- This environment is especially useful for comparing neural networks to more traditional statistical and machine learning models such as logistic regression or lasso regression, helping you to understand both the strengths and limitations of deep learning methods.
9.9 Convolutional Neural Networks (CNN)
Convolutional Neural Networks (CNNs) are a special type of neural network architecture designed for processing grid-like data, particularly images.
- CNNs excel at tasks such as image classification, object detection, and facial recognition by automatically learning useful visual features from pixel data.
- Unlike fully connected neural networks, where every neuron connects to every input value, CNNs apply learned filters (also called kernels) to small overlapping regions of the input image.
- As the filter moves across the image, the network computes weighted sums of the pixel values within each region using the learned filter parameters.
- The resulting values are passed through a nonlinear activation function, allowing the network to learn increasingly complex patterns and features.
- In mathematics, this sliding weighted-combination operation is called a Convolution, which gives Convolutional Neural Networks their name.
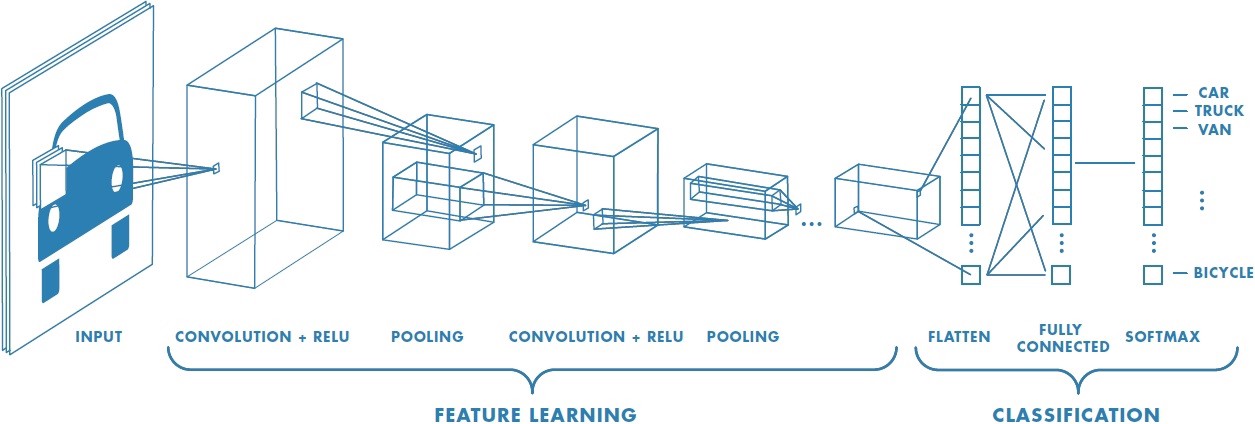
Figure 9.8 shows a typical CNN such as might be used for image classification (cat or dog).
9.9.1 Input Layer has Raw Pixel Data
On the left of Figure 9.8 is the input layer.
Every CNN begins with an input layer that takes in the image as a multi-dimensional array of pixel values.
- For a color image, this typically includes three channels, red, green, and blue, resulting in a 3D input tensor (height × width × channels).
- The numerical values represent the intensity of each pixel.
9.9.2 Convolutional Layers for Feature Detectors
The next major component of a CNN is a convolutional layer, and CNNs often contain several such layers stacked together.
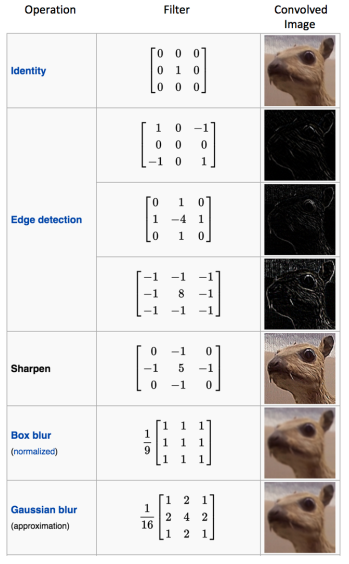
- A convolutional layer applies small, trainable filters (or kernels) that scan across the image to detect patterns and features.
- Each kernel performs an element-wise multiplication between the filter’s weights and a small region of the input image (for example, a \(3 \times 3\) patch of pixels).
- The resulting values are summed to produce a single activation value, which becomes one entry in the resulting feature map.
- The filter then moves across the image by a fixed number of pixels (called the stride) and repeats the process across the width and then height of the input.
- This continues until the filter has covered the entire image, producing a feature map: a 2D grid in which each value represents the strength or presence of a learned pattern at a particular location.
Key properties:
- Local connectivity: Filters examine local regions, preserving spatial relationships.
- Weight sharing: Each filter uses the same weights across the image, reducing model complexity.
- Depth: Multiple filters can be applied in a single convolutional layer, capturing various patterns simultaneously.
Early convolutional layers detect simple features like edges or colors; deeper layers detect more abstract concepts like shapes or object parts as shown in Figure 9.9.
9.9.3 Activation Functions enable Non-Linearity
After each convolution operation, an activation function, usually ReLU, is used to introduce non-linearity by zeroing out negative values:
- This allows the network to model complex patterns and relationships that simple linear transformations cannot.
9.9.4 Pooling Layers Reduce the Dimensions of the Network
Next come pooling layers, which reduce the spatial dimensions of the feature maps.
- The most common pooling operation is “max pooling”, which slides a small window (e.g., 2×2) over the feature map and takes the maximum value in each region.
- This step simplifies the data, makes the network more computationally efficient, and introduces a level of translation invariance.
Key benefits:
- Reduces the number of parameters.
- Controls overfitting.
- Preserves the most important features while discarding minor variations.
Pooling doesn’t alter the number of feature maps; it just compresses them.
9.9.5 Stacking Multiple Layers Enables Hierarchical Learning about Image Features
CNNs often stack multiple convolutional and pooling layers to learn a hierarchy of features in the image as in Figure 9.8:
- Shallow layers detect low-level features like edges and corners.
- Intermediate layers detect textures, patterns, and shapes.
- Deep layers capture high-level features and object parts.
This layered approach is what gives CNNs their strength in capturing complex patterns in images while reducing computations.
9.9.6 Fully-Connected Layers are then Used for Classification
After the final convolutional and pooling layers, the high-level feature maps are flattened into a single vector and passed into one or more fully-connected layers.
- These layers act like a traditional neural network, using the learned features to predict a class label or probability distribution over multiple categories (e.g., Dog, Cat, Tiger, Lion).
9.9.7 Output Layer
The final layer is often a softmax classifier (for multi-class classification), which outputs a probability score for each class.
- The highest score determines the predicted category of the image.
Note that kernels in CNNs are not the same as kernels in Support Vector Machines (SVMs):
- CNN kernels are learnable filters used to detect spatial patterns directly from input data.
- SVM kernels are mathematical functions (like polynomial) used to project data into higher-dimensional spaces to find separating boundaries.
While they share a name, they serve entirely different purposes in their respective algorithms.
CNNs are powerful for grid data because they combine:
- Local feature detection (via convolution),
- Efficient dimensionality reduction (via pooling),
- Non-linear transformations (via activation functions),
- and final classification (via fully connected layers).
This architecture allows them to automatically learn meaningful features and make accurate predictions from raw image data, without the need for manual feature engineering.
9.10 Transfer Learning and Pre-trained Models
9.10.1 Why Training from Scratch Is Rare
Training a network from scratch, initializing random weights and running gradient descent until convergence, is the process described throughout this chapter.
In practice, for most real-world problems in 2026, nobody does this.
The reason is scale.
- A frontier model like GPT-4 or Llama 3 has already consumed more text, images, or audio than any single organization could afford to process again.
- Its weight matrices encode an enormous amount of general knowledge about language, visual structure, or domain reasoning.
- Starting from random weights throws all of that away.
Instead, practitioners use one of three strategies, in increasing order of cost:
9.10.2 Three Strategies for Using Pre-Trained Models
9.10.2.1 Strategy 1 — Feature Extraction (freeze and predict)
Take a pre-trained model, remove its output layer, and treat the activations of the final hidden layer as a fixed feature vector.
- Train only a new output layer on your data.
- The pre-trained weights are frozen; they receive no gradient updates.
Characteristics:
- Cheapest: only the output layer parameters are learned.
- Works well when your data is small and similar to the pre-training domain.
- Example: use ResNet-50 (pre-trained on ImageNet) as a fixed feature extractor for a medical image classifier with only 500 labelled examples.
9.10.2.2 Strategy 2 — Fine-tuning
Start from a pre-trained model, then unfreeze some or all layers and continue training on your data with a very small learning rate \(\eta\) (see Table 9.9).
- The intuition: the pre-trained weights are already close to a good solution; large gradient steps would destroy that knowledge.
- Fine-tuning nudges them gently toward your specific task.
Characteristics:
- More expensive than feature extraction but often much better.
- A common pattern is to freeze early layers (which learn general low-level features) and fine-tune only the later layers (which learn task-specific features).
- Example: fine-tune BERT-base on a sentiment classification dataset with 5,000 labelled reviews.
In practice, deep learning frameworks allow each layer’s parameters to be marked as either trainable or non-trainable.
- Unfreezing a layer changes its parameters back to trainable so gradient descent can update them during optimization.
A common workflow is:
- Start with all pre-trained layers frozen.
- Train a new output layer on the target task.
- Unfreeze the final few layers of the network.
- Continue training with a small learning rate to fine-tune the model.
In Keras, layers can be marked as either trainable or non-trainable using the trainable attribute.
- A frozen layer does not update its weights during backpropagation:
- An unfrozen layer allows gradient updates during training:
- For example, a pre-trained model can initially be frozen:
Later, selected layers can be unfrozen for fine-tuning:
After changing trainability settings, the model should typically be recompiled so the optimizer recognizes which parameters should be updated.
9.10.2.3 Strategy 3 — Retrieval Augmented Generation (RAG)
For large language models, an alternative to retraining is to give the model access to a retrieval system at inference time.
- When a query arrives, relevant documents are fetched from a database and inserted into the model’s context window.
- The model’s weights are never modified; it answers using retrieved evidence rather than memorized knowledge.
Characteristics:
- No training cost at all.
- Best for knowledge-intensive tasks where facts change frequently (company documents, recent news, proprietary data).
- The model itself remains a black box; the retrieval system is the engineering challenge.
9.10.3 Pre-trained Model Families
Table 9.11 summarizes the major families in use as of the end of 2025.
| Family | Representative models | Pre-training domain | Typical downstream use |
|---|---|---|---|
| Vision CNNs | ResNet-50/101, EfficientNet, ConvNeXt | ImageNet (1.2M images, 1000 classes) | Image classification, object detection |
| Vision Transformers | ViT, CLIP (vision encoder) | ImageNet, image–text pairs | Image classification, zero-shot recognition |
| Language encoders | BERT, RoBERTa, DeBERTa | Masked language modelling on large text corpora | Text classification, NER, question answering |
| Language decoders | GPT-2, GPT-4, Llama 3, Mistral | Next-token prediction on web-scale text | Text generation, summarization, code |
| Multimodal | CLIP, Gemini, GPT-4o | Image–text pairs, video, audio | Cross-modal retrieval, image captioning, VQA |
All of these models are architecturally composed of the same building blocks covered in this chapter: linear combinations, activation functions (Equation 9.6, Equation 9.5), and output layers, just at a scale described by Table 9.2.
9.10.4 Hugging Face as a Model Registry
Hugging Face is the dominant public repository for pre-trained models, providing a standardized API (transformers, diffusers) to load, fine-tune, and deploy models with a few lines of Python or R code.
- As of 2025 it hosts over 900,000 public model checkpoints.
For most applied ML projects, the workflow is:
- Search Hugging Face for a model pre-trained on a domain similar to yours.
- Load the model and tokenizer/preprocessor.
- Fine-tune on your labelled data (Strategy 2 above) or attach a new output head (Strategy 1).
- Evaluate on held-out test data (Section 9.4).
This workflow is covered in detail in specialized NLP and computer vision courses; the key point here is that everything in this chapter, the loss functions, the backpropagation mechanics, the regularization and tuning decisions, applies equally when fine-tuning a pre-trained model.
- The only difference is the starting point of the weights.
9.11 Transformers: the Architecture Behind Frontier Models
The CNNs covered in Section 9.9 and the dense networks throughout this chapter are the foundations of deep learning.
But the architecture that underlies almost every frontier model in use in 2025, GPT-4, Llama 3, BERT, Gemini, Claude, is the Transformer, introduced by Vaswani et al. in 2017 in the paper “Attention is All You Need” (Vaswani et al. 2023).
9.11.1 What is Different about a Transformer?
A dense network processes each input independently: the computation for observation \(i\) does not depend on observation \(j\).
- For sequences, a sentence, a time series, a genome, this is a problem, because the meaning of a word depends on the words around it.
- Earlier solutions (recurrent networks, Holst) processed sequences one element at a time, passing a hidden state forward.
Transformers replace this with self-attention: every position in the sequence is allowed to “look at” every other position simultaneously, weighting the information it collects by learned relevance scores.
9.11.2 The Attention Operation
For a sequence of \(T\) tokens, self-attention computes three matrices from the input:
\[\mathbf{Q} = \mathbf{X}\mathbf{W}_Q, \quad \mathbf{K} = \mathbf{X}\mathbf{W}_K, \quad \mathbf{V} = \mathbf{X}\mathbf{W}_V \tag{9.12}\]
where \(\mathbf{W}_Q\), \(\mathbf{W}_K\), \(\mathbf{W}_V\) are learned weight matrices.
The attention output is:
\[\text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}\!\left(\frac{\mathbf{Q}\mathbf{K}^\top}{\sqrt{d_k}}\right)\mathbf{V} \tag{9.13}\]
- \(\mathbf{Q}\mathbf{K}^\top\) is a \(T \times T\) matrix of pairwise similarity scores between all positions, again, a matrix multiplication.
- The softmax (Equation 9.9) converts each row to a probability distribution: “how much should position \(i\) attend to position \(j\)?”
- Multiplying by \(\mathbf{V}\) produces a weighted average of the value vectors, where the weights are the attention probabilities.
Every operation in Equation 9.12 and Equation 9.13 is matrix algebra.
- The forward and backward passes are structurally identical to the examples, which is why the same GPU hardware (Note 9.1) that was designed for CNNs accelerates Transformers equally well.
You do not need to implement a Transformer in this course. But it is worth knowing that:
- The mathematical foundations, linear combinations, activation functions, softmax, cross-entropy loss, backpropagation, gradient descent, are exactly the same as in this chapter.
- Transformers are large (see Table 9.2), which is why transfer learning (Section 9.10) is the practical entry point for most applied work.
- The attention weights \(\text{softmax}(\mathbf{Q}\mathbf{K}^\top / \sqrt{d_k})\) are one of the few parts of a neural network that offer some interpretability:
- They show which parts of the input the model “looked at” when producing each output.
- This is a partial glimpse inside the black-box of large networks.
9.12 Responsible Data Science with Neural Networks
Neural networks are among the most powerful predictive tools available, but that power comes with obligations.
Before training a deep learning model, a responsible data scientist should work through four questions:
- Should I use a neural network at all?
- Can I explain what it does?
- Is the model fair to the people it affects?
- What are the environmental and resource costs?
This section addresses each in turn.
9.12.1 Do You Need a Neural Network?
The most important question is whether a simpler model would serve equally well.
- Neural networks carry real costs, computational, financial, environmental, and interpretability, that are only justified if they deliver meaningfully better performance for the task at hand.
Before committing to a neural network, ask:
| Question | If yes, consider instead |
|---|---|
| Is \(n\) small (< 1,000 obs) or \(p\) small (< 20 features)? | Logistic regression, LDA/QDA, Ridge/LASSO |
| Are the relationships between predictors and outcome roughly linear? | Linear or logistic regression with interactions |
| Is interpretability a hard requirement (e.g., medical, legal, financial)? | Logistic regression, decision tree, GAM |
| Is the performance gap between neural network and best linear model < 5%? | Use the linear model |
| Is the input structured tabular data (not images, text, or sequences)? | Gradient boosted trees (Boost, Limelight) often match neural networks on tabular data with far less tuning |
| Are training resources limited (time, compute, electricity)? | Start with a well-tuned linear or tree-based model |
The guiding principle is Occam’s razor applied to machine learning: prefer the simplest model whose performance is adequate for the task.
- A logistic regression that achieves 82% accuracy and whose coefficients can be explained to a stakeholder in plain language is often preferable to a neural network that achieves 84% accuracy and cannot.
Performance comparison in practice.
- As a sanity check, compare the neural network against simpler methods on the same data before concluding that the added complexity is warranted:
- Logistic regression: linear decision boundary; fully interpretable coefficients; trains in milliseconds
- LDA / QDA: assumes Gaussian class distributions; very fast; QDA adds non-linearity without the tuning burden of a neural network
- SVM with RBF kernel: captures non-linear boundaries; no probabilistic output but strong generalization with well-chosen \(C\) and \(\gamma\)
- Gradient boosted trees: handles non-linearity and interactions automatically; often the strongest baseline on tabular data; faster to tune than a deep network
- Neural network; justified when the above methods all plateau and the performance gain justifies the cost
If a logistic regression achieves the same AUC as your neural network (Table 9.6), deploy the logistic regression.
9.12.2 Explainability and Transparency
Neural networks are black-box models by default: the prediction for a given observation is the result of hundreds or thousands of interacting non-linear transformations, and no single weight has an interpretation analogous to a regression coefficient.
This matters whenever predictions affect people e.g., in credit scoring, medical diagnosis, hiring, or content recommendation.
Several post-hoc explainability tools partially address this:
| Method | What it explains | Limitation |
|---|---|---|
| SHAP (SHapley Additive exPlanations) | Feature-level contribution to each prediction; grounded in game theory | Computationally expensive for large networks; explains the model, not the true data-generating process |
| LIME (Local Interpretable Model-agnostic Explanations) | Locally approximates the model with an interpretable surrogate near a point of interest | Local approximation may not generalize; instability across runs |
| Attention weights | For Transformers (Section 9.11, Equation 9.13) determine which tokens influenced the output | Attention \(\neq\) explanation; high attention weight does not mean causal importance |
| Integrated Gradients | Attribution of prediction to input features via path integrals of gradients | Requires baseline choice; sensitive to saturation near Equation 9.6 dead zones |
| Saliency maps (CNNs, Section 9.9) | Which image pixels most influenced the prediction | Can highlight spurious features; adversarial examples can fool the map |
The key caution: post-hoc explainability tools explain the model’s behavior, not the underlying causal structure of the data.
- A SHAP value that says “feature \(X_3\) increased this prediction by 0.4” tells you about the model’s decision, not whether \(X_3\) caused the outcome.
- When causal inference or regulatory accountability is required, a neural network with SHAP is not a substitute for a well-specified regression model with domain knowledge.
Documentation and transparency. For any deployed model, document:
- The training data: its source, collection period, known biases, and exclusions
- The architecture and training procedure (hyperparameters from Table 9.9 and stopping criteria.
- Performance metrics on held-out test data (Table 9.5 or Table 9.6) disaggregated by subgroup where relevant
- Known failure modes and out-of-distribution behavior
This is sometimes called a Model Card ; a standardized one-page summary of what the model does, how it was trained, and where it should and should not be used.
9.12.3 Fairness and Bias
A neural network learns the patterns in its training data, including historical patterns that reflect systemic inequity.
- If the training data contains bias (e.g., hiring decisions made by biased humans, medical data collected from non-representative populations), the model will reproduce and potentially amplify that bias at scale.
Key sources of bias in neural network pipelines:
- Representation bias: the training sample does not reflect the deployment population. A model trained on patients from one hospital system may perform poorly on patients from another.
- Label bias: the outcome variable itself reflects historical human decisions that were biased (e.g., using past loan defaults as labels when lending was historically discriminatory).
- Proxy features: even after removing protected attributes (race, gender, age) from the input, neural networks can learn to use correlated features as proxies, reproducing discriminatory outcomes.
- Feedback loops: if a deployed model’s predictions influence future training data (e.g., a recommendation algorithm that determines what content users see), biases compound over time.
Fairness metrics that should be checked alongside accuracy, AUC, and RMSE:
| Metric | Definition | When to use |
|---|---|---|
| Demographic parity | \(P(\hat{Y}=1 \mid A=0) = P(\hat{Y}=1 \mid A=1)\) | When equal base rates across groups \(A\) are required |
| Equalized odds | Equal TPR and FPR across groups | When false negatives and false positives have asymmetric costs across groups |
| Calibration by group | Predicted probabilities match observed frequencies within each group | Whenever predicted probabilities are used for decisions |
| Individual fairness | Similar individuals receive similar predictions | Hard to operationalize without a similarity metric |
- No model is guaranteed fair simply because a protected attribute was excluded from the feature matrix.
- Fairness auditing requires deliberate, group-specific evaluation using the disaggregated metrics above.
9.12.4 Compute, Energy, and Environmental Cost
The scale table (Table 9.2) in the worked example shows that frontier models require billions of parameters and thousands of GPU-hours to train.
Even smaller models consume meaningful resources as seen in Table 9.14:
| Model scale | Approx. training energy | CO₂ equivalent |
|---|---|---|
| Our 10-obs example | < 1 watt-second | Negligible |
| ResNet-50 (25M params) | ~30 GPU-hours | ~3 kg |
| BERT fine-tuning | ~100 GPU-hours | ~10 kg |
| Training GPT-3 (175B) | ~3,640 MWh | ~550 tonnes |
| Training frontier model (~2T params) | Estimated 10,000–100,000 MWh | ~1,500–15,000 tonnes |
- For the scale of models trained in this course, small networks on tabular data, the energy cost is trivial.
- But the habit of asking “is this level of compute justified by the task?” scales to professional practice.
Practical guidelines:
- Establish a baseline first. Train the simplest model (Table 9.12) before a neural network. If the baseline is good enough, stop there.
- Use early stopping. Training far longer than necessary wastes compute and risks overfitting.
- Prefer fine-tuning over training from scratch (Section 9.10). Starting from a pre-trained model requires a fraction of the compute.
- Choose hardware appropriately. A small network on tabular data does not need a cloud GPU; a laptop CPU suffices. Reserve GPUs for models that genuinely need them.
- Report training costs alongside model performance in any publication or deployment documentation.
9.12.5 A Practical Decision Framework
The four considerations above can be summarized as a decision sequence to work through before and after training any neural network:
- Necessity: Is a neural network likely to outperform a well-tuned logistic regression, SVM, or gradient boosted tree on this data and task? If not, use the simpler model.
- Explainability requirement: Do stakeholders, regulators, or affected individuals have a right to an explanation of individual predictions? If yes, either use an interpretable model or commit to rigorous SHAP/LIME documentation.
- Fairness audit plan: Which subgroups are present in the data and the deployment population? Which fairness metric (Table 9.13) is appropriate for this decision context? Plan the evaluation before training.
- Compute budget: Is the training compute proportionate to the expected performance gain? Is fine-tuning (Section 9.10) a viable alternative to training from scratch?
After you train:
- Compare against baselines: Does the neural network outperform logistic regression / SVM / gradient boosted trees by a meaningful margin on the test set (Section 9.4)?
- Disaggregate metrics: Do performance metrics (Table 9.5, Table 9.6) hold across all relevant subgroups, or does the model perform well on average but poorly for a specific group?
- Document: Write the Model Card describing training data, architecture, metrics, known limitations.
- Revisit: Set a schedule to re-evaluate the model as the deployment distribution shifts over time.
9.13 From Neural Networks to Large Language Models and Agentic Systems
Everything in this chapter, weighted linear combinations, activation functions (Section 9.2.3), softmax outputs (Equation 9.9), cross-entropy loss, and backpropagation, is the mathematical substrate of the largest AI systems in deployment today.
Large Language Models (LLMs) such as GPT-4, Gemini, and Llama are Transformer networks (Section 9.11) scaled to hundreds of billions of parameters and trained on trillions of tokens of text.
Their forward pass is identical in structure to the multi-layer networks in this chapter:
- inputs are embedded as numeric vectors,
- passed through stacked layers of attention (Equation 9.13) and feed-forward sub-layers (each a dense layer with a non-linear activation), and
- a final softmax (Equation 9.9) converts the last layer’s output into a probability distribution over the vocabulary.
The model is trained by minimizing cross-entropy loss using mini-batch gradient descent (Section 9.3.1); exactly the procedure used to train smaller networks, just at the scale of Table 9.2.
An LLM with 70 billion parameters has \(7 \times 10^{10}\) weight values (\(w_{kj}\), \(\beta_k\), \(\mathbf{W}_Q\), \(\mathbf{W}_K\), \(\mathbf{W}_V\)) updated by backpropagation.
The update rule \(w \leftarrow w - \rho \frac{\partial \mathcal{L}}{\partial w}\) is unchanged; only the dimensionality of the gradient vector is larger by many orders of magnitude.
Agentic systems extend LLMs by embedding them inside a decision loop: the model generates not just text but actions, calling external tools (search engines, code interpreters, databases), receiving the results as new input, and iterating until a task is complete.
- From a statistical learning perspective, this is still function approximation: at each step the LLM computes \(f(X) = \hat{P}(\text{next token} \mid \text{context})\) (Equation 9.9), where the context now includes the history of actions and observations accumulated across the loop.
9.13.1 From a Prompt to a Paragraph: Token-by-Token Generation
When you submit a prompt to an LLM, say, “Write a Python function that reads a CSV file and returns the column means”, the model does not produce the entire response in one forward pass.
- Instead, it generates the response one token at a time, where a token is roughly a word or sub-word piece (e.g.,
"def"," read","_csv","(").
The mechanism is a direct application of the softmax output layer (Equation 9.9):
Tokenize the prompt. The input string is converted into a sequence of integer indices, one per token: \(\mathbf{x} = (x_1, x_2, \ldots, x_T)\), where \(T\) may be thousands of tokens for a long prompt or conversation history. This sequence is the context window.
Embed and encode. Each token index is mapped to a dense numeric vector (an embedding), and the full sequence is passed through the Transformer’s stacked attention and feed-forward layers (Section 9.11).
- The result is a single hidden-state vector \(\mathbf{h}_T \in \mathbb{R}^d\) summarizing the entire context.
Project to vocabulary logits. A final linear layer maps \(\mathbf{h}_T\) to a vector of raw scores \(\mathbf{z} \in \mathbb{R}^V\), one score per token in the vocabulary (typically \(V \approx 50{,}000\)–\(100{,}000\)).
Apply softmax to get a probability distribution.
\[\hat{P}(\text{next token} = v \mid \mathbf{x}) = \frac{e^{z_v}}{\sum_{v'=1}^{V} e^{z_{v'}}} \tag{9.14}\]
Sample or select the next token. The model either takes the highest-probability token (greedy decoding) or samples from the distribution (temperature sampling). Call this chosen token \(x_{T+1}\).
Append and repeat. \(x_{T+1}\) is appended to the context, \(T \leftarrow T+1\), and the entire forward pass is repeated from step 2.
- This loop continues until the model generates a special end-of-sequence token or a length limit is reached.
A response of 200 words therefore involves roughly 250–300 forward passes through the full network; each one a complete evaluation of all \(w_{kj}\), \(\beta_k\), \(\mathbf{W}_Q\), \(\mathbf{W}_K\), and \(\mathbf{W}_V\) matrices (Section 9.11).
When the context contains a programming instruction and the model has been trained on billions of lines of source code, the token probabilities at each step strongly favor syntactically consistent continuations
- After generating
```python, the next highest-probability token is almost always a valid Python keyword or identifier, not a random word. - The structured appearance of generated code is not a separate capability; it is the same softmax (Equation 9.14) operating over a context in which code tokens have dominated the training distribution for that type of prompt.
The responsible data science principles in Section 9.12 apply with even greater force to LLMs and agents.
- Explainability (Section 9.12.2): attention weights offer partial interpretability, but emergent multi-step reasoning in agents is far harder to audit than a single network’s predictions.
- Fairness (Section 9.12.3): training data at web scale encodes societal biases that propagate into every downstream application.
- Compute cost (Section 9.12.4): inference on frontier models — not just training — consumes substantial energy at population scale; every API call has a resource footprint.
You do not need to train an LLM to use one responsibly or to contribute to applications built on top of one.
What you do need is exactly what this chapter provides: a precise understanding of how weights are learned, what loss functions optimize, why regularization matters, and what the model cannot know about fairness or causality from data alone.
The practitioner who understands gradient descent and softmax is far better positioned to evaluate, fine-tune (Section 9.10), prompt-engineer, and audit these systems than one who treats them as oracles.
9.14 Summary of Neural Network Models for Deep Learning
Deep Learning and Neural Networks is a vast field of research and application.
- There are multiple variants for working with special classes of problems such as Convolutional Neural Networks, or building models upon model or models that compete with other models.
- While Deep Learning and Neural Networks can be a powerful method for prediction, it often of little help in inference as the models tend to be “black-box” models where explainability is hard.
Deep Learning and Neural Networks may also be dominated by other methods depending upon the data set and question to be answered.
- Once one considers constraints on the available resources in computational power/memory as well as the time it takes to properly tune a model for maximum performance, other methods are often much better choices if they perform reasonably well.
- The practical decision framework in Section 9.12 provides a structured checklist for deciding when a neural network is, and is not, the right tool, and how to evaluate it responsibly with respect to explainability (Section 9.12.2), fairness (Section 9.12.3), and compute cost (Section 9.12.4).
To reduce some of that time and expense, consider the three strategies covered in Section 9.10:
- feature extraction (freeze pre-trained weights, train only a new output head),
- fine-tuning (continue gradient descent from a pre-trained starting point with a very small learning rate), or,
- Retrieval Augmented Generation (RAG — no retraining at all; retrieve relevant documents at inference time).
Pre-trained models for almost every domain are available on Hugging Face.
- The architecture behind most of these frontier models is the Transformer (Section 9.11), whose forward and backward passes are structurally identical to what is covered in this chapter, just at a scale described by Table 9.2.
Machines may learn, but humans still need to know how to make choices to generate useful results.