Appendix A — A General Introduction to Matrices
A.1 Matrices, Vectors, and Scalars
A.1.1 Definition of a Matrix
A rectangular array is a set of numbers ( or symbols representing numbers) where the numbers are arranged in rows and columns where every column has the same number of rows and every row has the same number of columns.
A matrix is a rectangular array where each entry is called an element of the matrix. A matrix is often denoted by a capital letter, e.g., \(A\).
A.1.2 The Size or Dimension of a Matrix
The size or dimension of a matrix \(M\) is specified by the number of rows \(r\) and the number of columns \(c\) and is denoted as \((r\times c)\).
Alternative Notation: dim(\(M\)) = \(r\times c\)
Examples:
Matrix \(A\) has 3 rows and 2 columns so has size \((3 \times 2)\) or dim(\(A\)) = \(3 \times 2\).
\[ A = \begin{bmatrix} 1 &2 \\ 3 & 0 \\ -1 & 4 \end{bmatrix} \]
Define matrix B
Matrix \(B\) has 2 rows and 4 columns so has size \((2 \times 4)\) or dim(\(B\)) = \(2 \times 4\).
\[ B = \begin{bmatrix}a & b & c & d \\e & f & g & h\end{bmatrix} \]
A.1.3 Row and Column Vectors
When a matrix only has one row it may be called a row vector with dimension \((1 \times m)\). A vector \(V\) may be denoted by \(\vec{V}\).
- Think of the row vector as a row in a spreadsheet that contains all the values of the variables/attributes for one case or observation.
\[ \vec{R} = \begin{bmatrix}0 & -2 & 0 & 1 \end{bmatrix} \]
When a matrix only has one column, it may be called a column vector with dimensions \((n \times 1)\).
- Think of a column vector as a column in a spreadsheet with the values of the observations for one variable/attribute.
\[ \vec{C} = \begin{bmatrix*}[r]10 \\ -2 \\ 0 \\ 1\end{bmatrix*} \]
A.1.4 Scalars
A scalar is a matrix of size \((1 \times 1)\) and is usually displayed as just the value as a real number.
ex. \(k = \sqrt{2}\) is a scalar.
Warning
In the programming language R, a \((1 \times 1)\) data frame is not the same as a single value. It is still of class data frame.
A.1.5 General Notation for a Matrix
If matrix \(A\) has \(n\) rows and \(m\) columns, so dimension \((n \times m)\), each entry is called an element of \(A\) and its position in the matrix is denoted using subscripts. The notation \(a_{ij}\) identifies the element at the intersection of row \(i\) and column \(j\).
\[ A = \begin{bmatrix}a_{11}&a_{12}&\cdots &a_{1m} \\ a_{21}&a_{22}&\cdots &a_{2m} \\ \vdots & \vdots & \ddots & \vdots\\a_{n1}&a_{n2}&\cdots &a_{nm}\end{bmatrix} \]
or, in shorthand, \(A_{n\times m}\) is the set of \(a_{ij}\) (where \(\{\dots\}\) denotes a set), e.g., \[A = \left\{a_{ij}\right\} \quad i = 1, \dotsc, n, \quad j = 1, \dotsc, m\]
At times you may see the dimension of matrix indicated using a subscript so \(A_{n\times m}\) means \(A\) is a matrix with \(n\) rows and \(m\) columns.
A.2 Special Matrices
A.2.1 A Square Matrix
A square matrix is a matrix with the same number of columns and rows, i.e., of size \(n \times n\). A square matrix of size \(n \times n\) is said to be of order \(n\).
\[ Q = \begin{bmatrix}1 & 2 \\3 & 4\end{bmatrix} \]
A.2.1.1 Determinants of Square Matrices
- Given a square matrix, one can calculate a scalar number known as the determinant of the matrix. The determinant of matrix \(A\) is denoted in several ways: \(det(A) = |A|\) or for a \(2 \times 2\) matrix as
\[ det(A) = det\begin{bmatrix} 1 & 3 \\ 2 & 4 \end{bmatrix} = \begin{vmatrix} 1 & 3 \\ 2 & 4 \end{vmatrix} \]
The determinant “determines” or describes how the matrix structure may affect other matrices when used in operations.
The determinant of a matrix can be calculated using only the numbers in the matrix.
For a matrix of order 2, the calculation is straightforward:
\[ det(A) = \begin{vmatrix}a_{11} & a_{12}\\a_{21} & a_{22}\end{vmatrix} = a_{11}a_{22} - a_{12}a_{21} \]
- For higher order matrices, the calculations get more complicated.
A.2.2 A Symmetric Matrix
A symmetric matrix \(A\) is a square matrix where the elements that correspond by switching \(i\) and \(j\) are equal.
\[ \left\{a_{ij}\right\}=\left\{a_{ji}\right\} \text{ for all } i = 1, \dotsc, n, \quad j = 1, \dotsc, n \]
\[ A = \begin{bmatrix}1 & 2 & 3 & 4 \\ 2 & 5 & 8 & 9 \\3 & 8 & 7 & 10 \\4 & 9 & 10 & 11 \\\end{bmatrix} \]
A.2.3 A Diagonal Matrix
A diagonal matrix is a square matrix \((n \times n)\) where all the off diagonal elements are 0, i.e., the only non-zero elements are on the diagonal where \(i = j\).
\[ D = \begin{bmatrix}1 & 0 & 0 & 0 \\0 & 3 & 0 & 0 \\0 & 0 & -2 & 0 \\0 & 0 & 0 & 10 \\ \end{bmatrix} \]
NoteDiagonal matrices are also symmetric.
A.2.4 The Identity Matrix
The Identity matrix is a diagonal matrix where every diagonal value is equal to 1 and all off-diagonal elements are 0.
\[ I = \begin{bmatrix}1 & 0 & 0 & 0 \\0 & 1 & 0 & 0 \\0 & 0 & 1 & 0 \\0 & 0 & 0 & 1 \end{bmatrix} \]
A.2.5 The \(1_n\) and \(0_n\) Vectors
A column vector of all 1s of size \((n×1)\) is denoted as
\[ 1_n = \begin{bmatrix} 1_1 \\ 1_2\\ \vdots \\ 1_n \\ \end{bmatrix} = \vec{1} \]
A column vector of all 0s of size \((n×1)\) is denoted as
\[ 0_n = \begin{bmatrix} 0_1 \\ 0_2\\ \vdots \\ 0_n \\ \end{bmatrix} = \vec{0} \]
A.3 Matrix Operations
A.3.1 Equality of Matrices
Definition: Two matrices \(A\) and \(B\) are said to be equal, denoted as \(A = B\), if
\[ \left\{a_{ij}\right\}=\left\{b_{ij}\right\} \text{ for all } i = 1, \dotsc, n, \quad j = 1, \dotsc, m \]
Note
For two matrices to be equal they must be of the same size (dimension).
Example: If
\[ A = \begin{bmatrix}1 &2 \\3 & 0 \\-1 & 4\end{bmatrix} \text{ and } B = \begin{bmatrix}x &4/2x \\ \sqrt{9} & 2-2x \\3-4 & 2^{2x}\end{bmatrix} \]
then \(A = B\) if \(x = 1\).
A.3.2 Addition of Matrices
To add two matrices \(A,B\), they must have the same size, i.e., i.e., dim(\(A\))=dim(\(B\)) = \(n \times m\).
The addition of two matrices, \(A+B\), results in the matrix \(S\) where each element of \(S\) is equal to the sum of the two corresponding elements of \(A\) and \(B\).
\[ S = A + B \equiv \left\{ s_{ij} = a_{ij} + b_{ij}\right\} \text{ for all } i = 1, \dotsc, n, \quad j = 1, \dotsc, m \]
Example: if
\[ A= \begin{bmatrix}1&2 \\3&0 \\-1 &4\end{bmatrix}\text{ and } B = \begin{bmatrix}-1&4 \\6&0 \\2 &-3\end{bmatrix} \]
then
\[ A + B = \begin{bmatrix}1 + (-1)&2 + 4 \\3 + 6&0 + 0 \\-1 + 2 &4 + (-3)\end{bmatrix} = \begin{bmatrix}0&6 \\9&0 \\1 &1\end{bmatrix} = S \]
A.3.3 Multiplying a Matrix by a Scalar
Let \(k\) be any real number (a scalar) and \(A\) a matrix of size \(n \times m\).
Multiplying a matrix by a scalar results in a matrix where every element has been multiplied by the scalar.
\[ kA= \left\{ ka_{ij} \right \} \text{ for all } i = 1, \dotsc, n, \quad j = 1, \dotsc, m \]
Example for matrix \(A\),
\[ \frac{1}{2}A= \frac{1}{2}\begin{bmatrix}1&2 \\3&0 \\-1 &4\end{bmatrix} = \begin{bmatrix}\frac{1}{2}(1)&\frac{1}{2}(2) \\\frac{1}{2}(3)&\frac{1}{2}(0)\\ \frac{1}{2}(-1) &\frac{1}{2}(4)\end{bmatrix} = \begin{bmatrix}\frac{1}{2}& 1 \\ \frac{3}{2}&0 \\ -\frac{1}{2} & 2\end{bmatrix} \]
Note
Scalar multiplication is commutative: \(kA = Ak\)
A.3.4 Multiplying a Matrix by another Matrix
A.3.4.1 Definition
Let \(A\) be an \(n \times m\) matrix and \(B\) be a \(m \times k\) matrix.
Note
To multiply two matrices \(A \text{ and } B\), the number of columns in \(A\) must equal the number of rows in \(B\), as seen here where \(m=m\).
Multiplying \(A\) \((n \times m)\) times \(B\) \((m \times k)\), denoted as \(AB\), results in a matrix \(M\) of dimension \((n \times k)\) where \(m_{ij}\) is the sum of the product of the corresponding elements in row \(i\) from \(A\) with the elements in the column \(j\) from \(B\) such that
\[ AB= M \equiv \left\{ m_{ij} \right \} \text{ for all } i = 1, \dotsc, n, \quad j = 1, \dotsc, m \]
where
\[ m_{ij} = (a_{i1}b_{1j} + a_{i2}b_{2j} + \cdots + a_{im}b_{mj}) = \sum_{k=1}^{m} a_{ik}b_{kj} \]
Example:
\[ \text{ Let } A = \begin{bmatrix} 1 &2 \\ 3 & 0 \\-1 & 4\end{bmatrix} \text{ and } B = \begin{bmatrix}2 &4 & 6 & 8 \\ 1 & 3 & 5 & 9\end{bmatrix} \]
Here dim(\(A\)) = \(3 \times 2\) and dim(\(B\)) = \(2 \times 4\).
Therefore,
\[ \begin{align} AB &= \begin{bmatrix}1(2) + 2(1) &1(4) + 2(3) & 1(6) + 2(5) & 1(8) + 2(9) \\ 3(2) + 0(1) & 3(4) + 0(3) & 3(6) + 0(5) & 3(8) + 0(9)\\ -1(2) + 4(1) & -1(4) + 4(3) & 1(6) + 4(5) & -1(8) + 4(9) \end{bmatrix} \\ & = \begin{bmatrix} 4 & 10 & 16 & 26 \\ 6 & 12 & 18 & 24 \\ 2 & 8 & 14 & 28 \end{bmatrix}\end{align} \]
A.3.4.2 Properties
Matrix multiplication is not commutative! If dim(\(B\)) = \(m \times k\) and dim(\(A\)) = \(n \times m\), the product \(BA\) does not exist when \(k \neq n\). If the \(A\) and \(B\) are both square with the same dimension then \(BA\) may exist but it is not necessarily true that \(BA = AB\).
Matrix multiplication is distributive under matrix addition such that for three matrices of the correct sizes, \(A(B+C) = AB + AC\).
A.3.4.3 Exercises
A.3.4.3.1 Is matrix multiplication commutative?
\[ \text{Let } C = \begin{bmatrix} 1 & 4 \\ 2 & 3 \end{bmatrix} \text{ and } D = \begin{bmatrix} 4 & 3 \\ 5 & 4 \end{bmatrix} \]
Compute \(CD\) and \(DC\) and check if \(CD = DC\).
CautionSolution
\[ CD = \begin{bmatrix}1(4) + 4(5) & 1(3)+ 4(4) \\ 2(4) + 3(5) & 2(3) + 3(4)\end{bmatrix} = \begin{bmatrix}24 & 19 \\ 23 & 18\end{bmatrix} \]
and
\[ DC = \begin{bmatrix} 4(1) + 3(2) & 4(4)+ 3(3) \\ 5(1) + 4(2) & 5(4) + 4(3) \end{bmatrix} = \begin{bmatrix}10 & 25 \\ 13 & 32\end{bmatrix} \]
Warning
In matrix multiplication, order matters! Often \(BA \neq AB\).
A.3.4.3.2 Is matrix multiplication distributive?
\[ \text{Let } A = \begin{bmatrix}1 &2 \\ 3 & 0 \\-1 & 4\end{bmatrix} \quad B = \begin{bmatrix}2 &4 & 6 & 8 \\ 1 & 3 & 5 & 9\end{bmatrix} \text{ and } C = \begin{bmatrix}1 & 2 & 3 & 4 \\ 5 & 4 & 3 & 2\end{bmatrix} \]
Check if \(A(B+C) = AB + AC\)
CautionSolution
\[ A(B+C) = \begin{bmatrix} 1 &2 \\ 3 & 0 \\ -1 & 4 \end{bmatrix} \begin{bmatrix} 3 & 6 & 9 & 12 \\ 6 & 7 & 8 & 11 \end{bmatrix} = \begin{bmatrix} 15 & 20 & 25 & 34 \\ 9 & 18 & 27 & 36 \\ 21 & 22 & 23 & 32 \end{bmatrix} \]
\[ AB + AC = \begin{bmatrix} 4 & 10 & 16 & 26 \\ 6 & 12 & 18 & 24 \\ 2 & 8 & 14 & 28 \end{bmatrix} + \begin{bmatrix} 11 & 10 & 9 & 8 \\ 3 & 6 & 9 & 12 \\ 19 & 14 & 9 & 4 \end{bmatrix} = \begin{bmatrix} 15 & 20 & 25 & 34 \\ 9 & 18 & 27 & 36 \\ 21 & 22 & 23 & 32 \end{bmatrix} \]
A.3.4.4 Matrix Multiplication Terminology
\(AB\) means we are pre-multiplying \(B\) by \(A\).
\(BA\) means we are post-multiplying \(B\) by \(A\).
Depending upon the sizes of \(A\) and \(B\), neither \(AB\) or \(BA\) may exist or, if they exist, they may not be equal.
A.4 The Transpose of a Matrix
A.4.1 Definition
Let \(A\) be an \(n \times m\) matrix.
The transpose of \(A\), denoted as \(A^\intercal\) or \(A'\), is the \(m \times n\) matrix created by switching the columns of \(A\) to become the rows of \(A^\intercal\). It can also be considered as rotating or flipping \(A\) about its diagonal.
If \(A=\left\{a_{ij}\right\}\) then \(A^\intercal=\left\{a_{ji}\right\} \text{ for all } i = 1, \dotsc, n, \quad j = 1, \dotsc, m\)
If
\[ A= \begin{bmatrix} a_{11} &a_{12} &\cdots & a_{1m} \\ a_{21} &a_{22} &\cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots\\ a_{n1} & a_{n2} & \cdots & a_{nm} \end{bmatrix} \]
Then
\[ A^\intercal = \begin{bmatrix}a_{11}&a_{21}&\cdots &a_{n1} \\ a_{12}&a_{22}&\cdots &a_{2n} \\ \vdots & \vdots & \ddots & \vdots\\ a_{1m}&a_{2m}&\cdots &a_{mn}\end{bmatrix} \]
Example:
\[ \text{ If }A= \begin{bmatrix} 1 & 2 \\ 3 & 0 \\-1 & 4 \end{bmatrix} \text{ then } A^\intercal = \begin{bmatrix} 1 & 3 & -1 \\ 2 & 0 &4 \end{bmatrix} \]
Note
The transpose of a matrix always exists.
Tip
It is common in print to see column vectors represented as their transpose e.g., \[\vec{C} = \begin{bmatrix}1\\2\\3\end{bmatrix} = \begin{bmatrix}1&2&3\end{bmatrix}^\intercal\]
A.4.2 Properties of a Transpose
- Identity:
\(A^\intercal = A\) if an only if \(A\) is symmetric.
\[ \text{ If }S = \begin{bmatrix} 1 & 2 & 3 \\ 2 & 4 & 6 \\ 3 & 6 & 0 \end{bmatrix} \text{ then } S^\intercal = \begin{bmatrix} 1 & 2 & 3 \\ 2 & 4 & 6 \\ 3 & 6 & 0 \end{bmatrix} = S \]
- Transpose under Multiplication
\((AB)^\intercal = B^\intercal A^\intercal\)
Warning
Notice when taking the transpose of a product, we switch the order when multiplying the product of the transposes.
Example:
\[ \text{Let } A = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} \text{ and } B =\begin{bmatrix} 1 \\ -1 \end{bmatrix} \]
so
\[ A^\intercal = \begin{bmatrix} 1 & 3 \\ 2 & 4 \end{bmatrix} \text{ and } B^\intercal =\begin{bmatrix} 1 & -1 \end{bmatrix} \]
Then
\[ AB = \begin{bmatrix} 1(1) + 2(-1) \\ 3 (1) + 4 (-1) \end{bmatrix} =\begin{bmatrix} -1 \\ -1 \end{bmatrix} \text{ and } (AB)^\intercal = \begin{bmatrix} -1 & -1 \end{bmatrix} \]
So
\[ B^\intercal A^\intercal = \begin{bmatrix} 1 -1 \end{bmatrix} \begin{bmatrix} 1 & 3 \\ 2 & 4 \end{bmatrix} = \begin{bmatrix} 1 (1) + 1(2) & 1(3) + -1(4) \end{bmatrix} = \begin{bmatrix} -1 & -1 \end{bmatrix} \]
\[ \implies (AB)^\intercal = B^\intercal A^\intercal \]
Note
This property is often used, going both ways, in regression. You should be familiar with it.
A.5 More on the Determinant of A Square Matrix
- If \(A\) is any square matrix that contains a row (or column) or zeros, then \(det(A)\) = 0.
Example: Let
\[ F = \begin{bmatrix} 1 & 2 & 3 & 4 \\0 & 0 & 0 & 0 \\2 & 0 & -2 & 0 \\1 & 1 & -5 & 10 \\ \end{bmatrix} \]
Then \(det(F)\) = 0.
- If \(D\) is an \(n \times n\) diagonal matrix, then \(det(D)\) is the product of the entries on the main diagonal, i.e.,
\[ det(D) = d_{11}d_{22}d_{33} ... d_{nn} \]
Example: Let
\[ D = \begin{bmatrix} 1 & 0 & 0 & 0 \\0 & 3 & 0 & 0 \\0 & 0 & -2 & 0 \\0 & 0 & 0 & 10 \\ \end{bmatrix} \] \[det(D) = 1(3)(-2)(10) = -60.\]
- If \(A\) and \(B\) are square matrices of the same size, then \(det(AB) = det(A)det(B).\)
A.6 The Inverse of a Matrix
A.6.1 Definition
A matrix \(B\) is said to be the inverse of the matrix \(A\) if
\[ AB = I_n \text { and } BA = I_n \]
If \(B\) is the inverse of \(A\) we denote the inverse as \(B = A^{-1}\)
A.6.2 Remarks
- Only square matrices can have inverses.
- Not All square matrices have inverses.
- If \(A^{-1}\) exists for matrix \(A\), then the inverse \(A^{-1}\) is unique.
- If a matrix \(A\) has an inverse, we say \(A\) is invertible.
- Matrix \(A\) is invertible, if and only if \(det(A) \neq 0\).
Proof:
If \(A\) is an \(n \times n\) invertible matrix, then there exists an \(n \times n\) matrix \(A^{-1}\) such that \(AA^{-1} = I_n\),
where the identity matrix \(I_n\) is a diagonal matrix with all 1’s on the diagonal.
\[det(AA^{-1}) = det(A)det(A^{-1}) = det(I_n) = 1\] Consequently \(det(A) \neq 0\).
- When \(det(A) = 0\) that means at least one row of the matrix can be calculated as a linear combination of other rows in the matrix. If \(det(A) = 0\), then we say the matrix \(A\) is singular or non-invertible.
- If \(A\) is invertible, then the matrix equation \(AX = B\) has a unique solution.
A.6.3 Calculating the Inverse of a Matrix
Calculating the inverse of a matrix of order 2 is straightforward:
\[ \text{If } A = \begin{bmatrix} a&b\\ c&d \end{bmatrix} \text { then } A^{-1} = \frac{1}{det(A)}\begin{bmatrix} d&-b\\ -c&a \end{bmatrix} = \frac{1}{ad-bc}\begin{bmatrix} d&-b\\ -c&a \end{bmatrix} \]
Note
Since the \(det(A)\) appears in the denominator, when \(det(A) = 0\), \(A^{-1}\) does not exist.
Warning
When calculating the determinant (or inverse) of a matrix using a computer, especially when the matrix is large or has values that differ by several orders of magnitude, special techniques are required to minimize the risk of getting values of 0 or close to 0 just due to the limited precision of a computer.
Example:
\[ \text{Let } A = \begin{bmatrix}1&2\\ 3&4 \end{bmatrix} \text { then } det(A) = (1(4) - 2(3)) = -2 \]
Define matrix \(B\) as:
\[ B = \frac{1}{-2}\begin{bmatrix} 4&-2\\ -3&1 \end{bmatrix} = \begin{bmatrix} -2&1\\ 3/2 &-1/2 \end{bmatrix} \]
Then
\[ \begin{align*}AB &= \begin{bmatrix} 1&2\\ 3&4 \end{bmatrix} \begin{bmatrix} -2&1\\ 3/2&-1/2 \end{bmatrix} = \begin{bmatrix} 1(-2) + 2(3/2) & 1(1) + 2(-1/2)\\ 3(-2) + 4(3/2) &3(1) + 4(-1/2) \end{bmatrix}\\& = \begin{bmatrix} 1 & 0\\ 0 &1 \end{bmatrix} = I_2\end{align*} \]
and
\[ \begin{align*}BA &= \begin{bmatrix} -2&1\\ 3/2&-1/2 \end{bmatrix} \begin{bmatrix} 1&2\\ 3&4 \end{bmatrix}= \begin{bmatrix} -2(1) + 1(3) & -2(2) + 1(4)\\ (3/2)(1) + (-1/2)(3) &(3/2)(2) + (-1/2)(4) \end{bmatrix}\\ & = \begin{bmatrix} 1 & 0\\ 0 &1 \end{bmatrix} = I_2 \end{align*} \]
\[ \implies B = A^{-1} \text{ and } A^{-1} = B \]
A.6.4 Properties of the Inverse
Assuming an \(A\), \(B\) and \(AB\) are invertible matrices, (i.e., \(A^{-1}\), \(B^{-1}\), and \((AB)^{-1}\) exist), then
- \((A^{-1})^{-1} = A\)
- \((AB)^{-1} = B^{-1}A^{-1}\)
Warning
Notice when taking the inverse of a product, we switch the order when multiplying the product of the inverses.
A.6.4.1 Orthogonality
- If \(C\) is an \(n\times n\) matrix, \(C\) is said to be orthogonal if \(C^\intercal C = I_n\).
- An \(n\times n\) matrix \(C\) is orthogonal if and only if \(C^{-1} = C^\intercal\).
- The determinant of an orthogonal matrix is either 1 or -1.
- Orthogonal matrices have nice properties such as enabling numerical stability in computer-based linear regression algorithms.
A.7 Linear Independence and the Rank of a Matrix
A.7.1 Definition of Linear Independence
Let \(\vec{V}_1, \vec{V}_2, \dotsc, \vec{V}_m\) be \(m\) vectors and \(k_1, k_2, \dotsc, k_m\) be \(m\) scalars.
The vectors \(\vec{V}_1, \vec{V}_2, \dotsc, \vec{V}_m\) are said to be linearly dependent if there exists some \(k_i's \neq 0\quad i = 1, 2 \dotsc, m\) such that the linear combination:
\[ k_1\vec{V}_1 + k_2 \vec{V}_2 + \cdots + k_m \vec{V}_m = \vec{0} = 0_m \]
Note
If the vectors \(\vec{V}_1, \vec{V}_2, \dotsc, \vec{V}_m\) are linearly dependent, this implies there is at least one of the vectors \(\vec{V}_i\) which can be expressed (calculated) as a linear combination of one or more of the other vectors.
Practical Interpretation: If a set of vectors is linearly dependent, then at least one of the vectors is redundant (does not add any new information to the other vectors).
Example:
\[ \text{Let } S = \begin{bmatrix}1&2&3\\ 2&4&6\\ 3&6&0 \end{bmatrix}\text{ with row vectors } \begin{matrix}\vec{V}_1 & = \begin{bmatrix} 1&2&3 \end{bmatrix}\\ \vec{V}_2 & = \begin{bmatrix} 2&4&6 \end{bmatrix}\\ \vec{V}_3 & = \begin{bmatrix} 3&6&0 \end{bmatrix}\end{matrix} \]
\[ \vec{V}_2 = 2\vec{V}_1 \implies (-2)\times \vec{V}_1 + 1 \times \vec{V}_2 + 0\times \vec{V}_3 = \vec{0} \implies \text{ the vectors are linear dependent} \]
If a set of vectors \(\vec{V}_1, \vec{V}_2, \dotsc, \vec{V}_m\) are not linearly dependent, they are said to be linearly independent.
Practical Interpretation: If a set of vectors is linearly independent, then all vectors contribute new information.
Note
Either row vectors or column vectors can be linearly dependent.
- Row vectors: Cases can be repeated so have identical information.
- Column vectors: Variables contain similar or redundant information.
A.7.2 Definition of the Rank of a Matrix
The rank of a matrix is the maximum number of linearly independent columns (rows).
A.7.3 Properties
- The inverse of a \(n\times n\) matrix \(Q\) exists if an only if \(rank(Q) = n\). We say \(Q\) is of full rank.
- For an \(n\times m\) matrix \(A\), \(rank(A) \leq min\left\{n,m\right\}\).
- if \(C = AB\), then \(rank(C) \leq min\left\{rank(A),rank(B) \right\}\).
A.8 Probability Results for Random Vectors
A.8.1 Definitions for a Random Vector.
Let \(X_1, X_2, \dotsc, X_k\) be a set of \(k\) random variables.
A vector \(X\) is a random vector when each element \(X_i\) is a random variable, e.g.,
\[ \vec{X} = \begin{bmatrix} X_1\\ X_2\\ \vdots\\ X_k \end{bmatrix} \text{ is a random vector.} \]
Note
Since each random variable \(X_i\) has a probability distribution, the random vector \(X\) has what we refer to as a joint distribution.
The joint distribution describes how the \(\left\{X_1, X_2, \dotsc,X_k\right\}\) are distributed in relation to one another.
Given a random vector \(\vec{X}\),
- The expected value of \(\vec{X}\) is the mean vector of \(\vec{X}\) and represents the center of the joint distribution of \(\vec{X}\). This is denoted as:
\[ \vec{\mu}_{\vec{X}} = E(\vec{X}) = \begin{bmatrix} E(X_1)\\ E(X_2)\\ \vdots\\ E(X_k) \end{bmatrix} \]
- Given a \(k\)-dimensional random variable \(X\), there exists a \(k\times k\) symmetric matrix, \(Cov(X)\), called the variance-covariance or covariance matrix of \(X\). It has the form:
\[ Cov(X) = \begin{bmatrix} Var(X_1) & Cov(X_1, X_2) & \cdots & Cov(X_1, X_k) \\ Cov(X_2,X_1) & Var(X_2) & \cdots & Cov(X_2, X_k) \\ \vdots & \vdots & \vdots & \vdots \\Cov(X_k,X_1)& Cov(X_k, X_2) & \cdots & Var(X_k) \end{bmatrix} \tag{A.1}\]
Note
\(Var(X_i)\) is equivalent to the variance of just the random variable \(X_i\) itself.
\(Cov(X_i, X_j) = E[(X_i - E[X_i])(X_j - E[X_j]) = E[(X_i - \mu_i)(X_j - \mu_j)]\) provides us information on how the random variables \(X_i, X_j\) are related (distributionally).
If \(Cor(X_i, X_j) = \frac{Cov(X_i, X_j)}{\sqrt{Var(X_i)Var(X_j)}} = 0\), then \(X_i, X_j\) are uncorrelated.
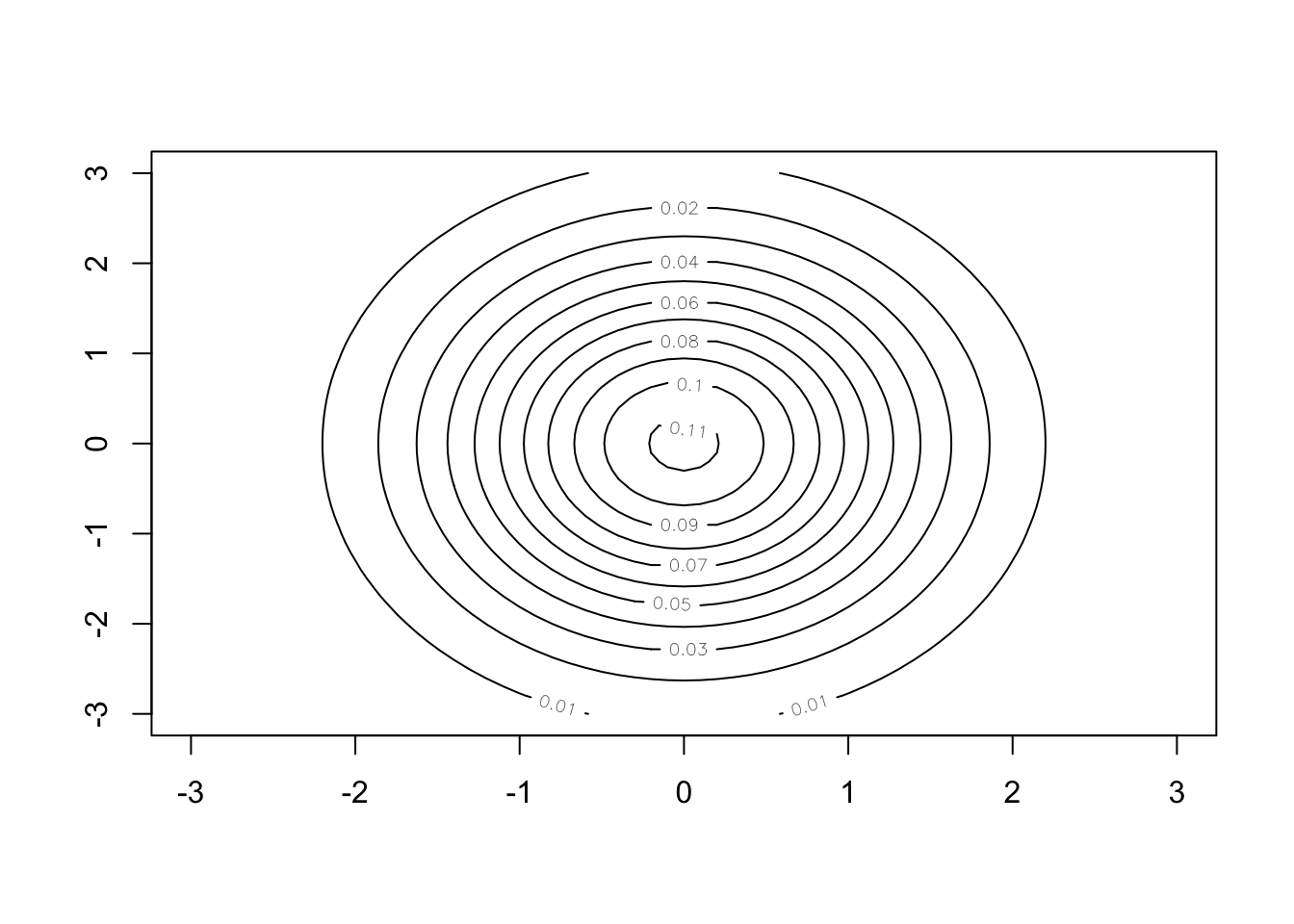
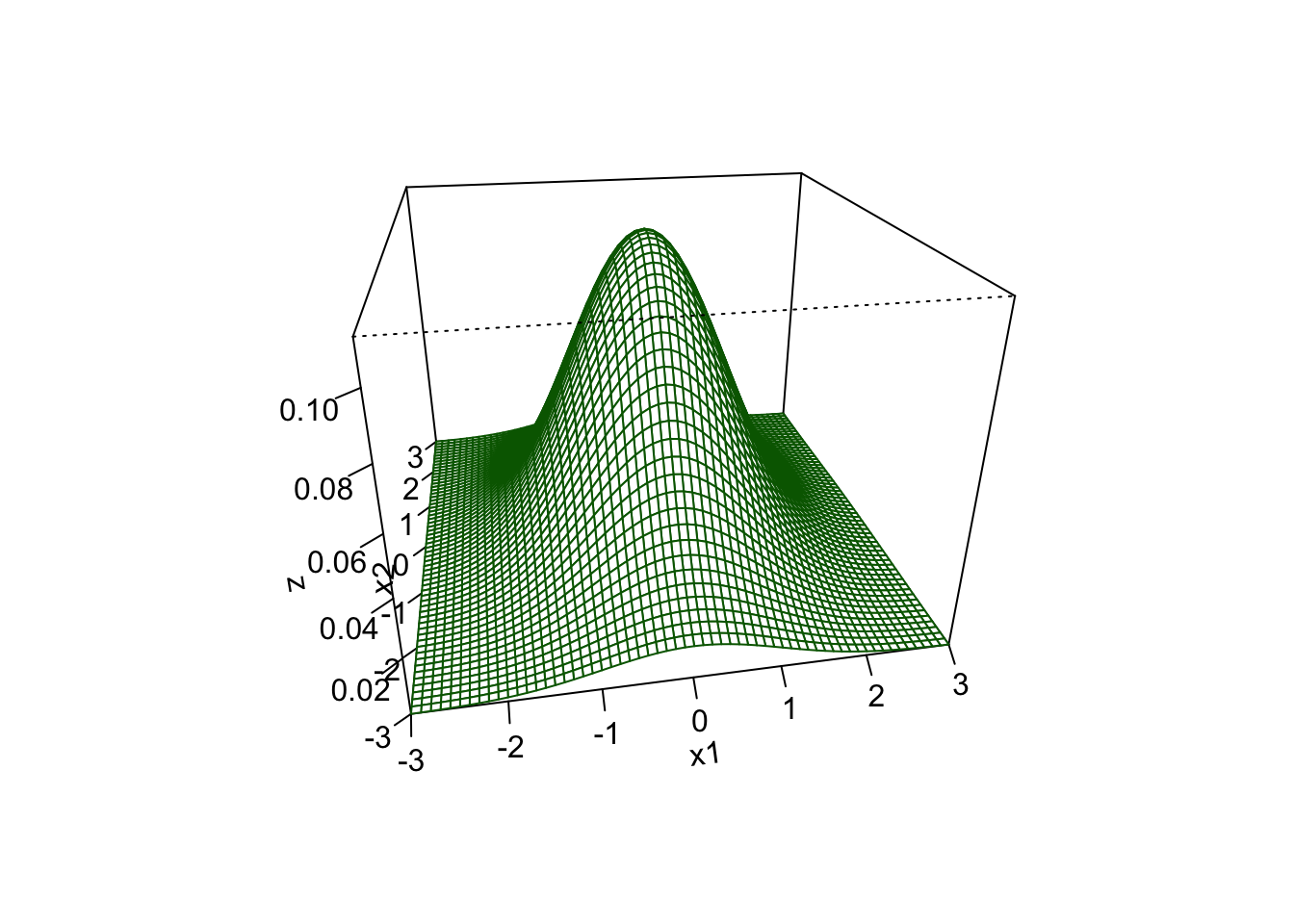
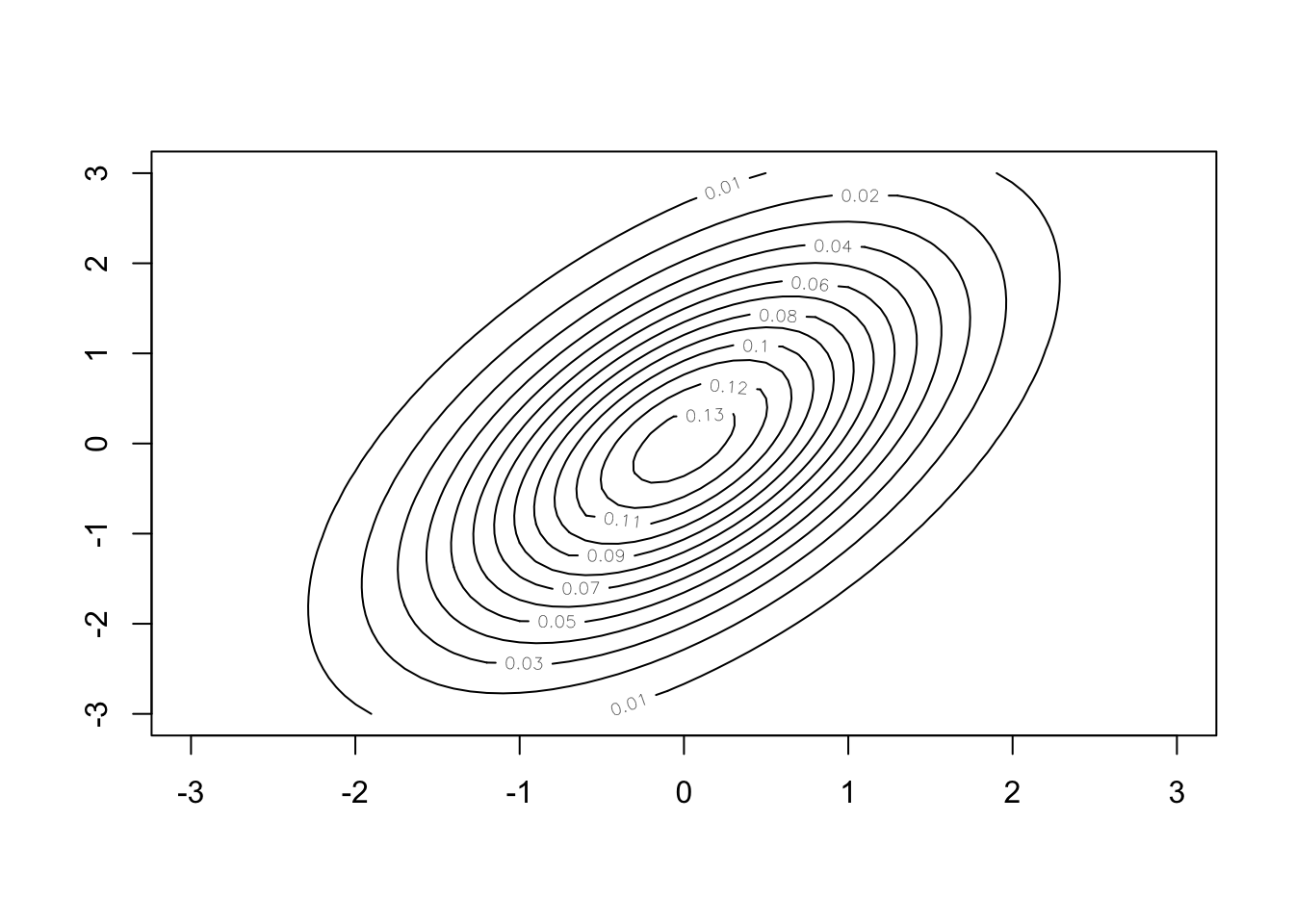
Example: Contour and surface plots of the joint density function of two normally distributed random variables with a joint distribution.
- In the first case, the two variables are independent, i.e., covariance is 0. The contour plot makes it easy to see \(\text{Var}(X_2) > \text{ Var}(X_1)\).
- In the second case, the covariance is greater than zero. The contour plot shows how the values of \(X_1\) and \(X_2\) are related and that creates an angle in the joint density function.
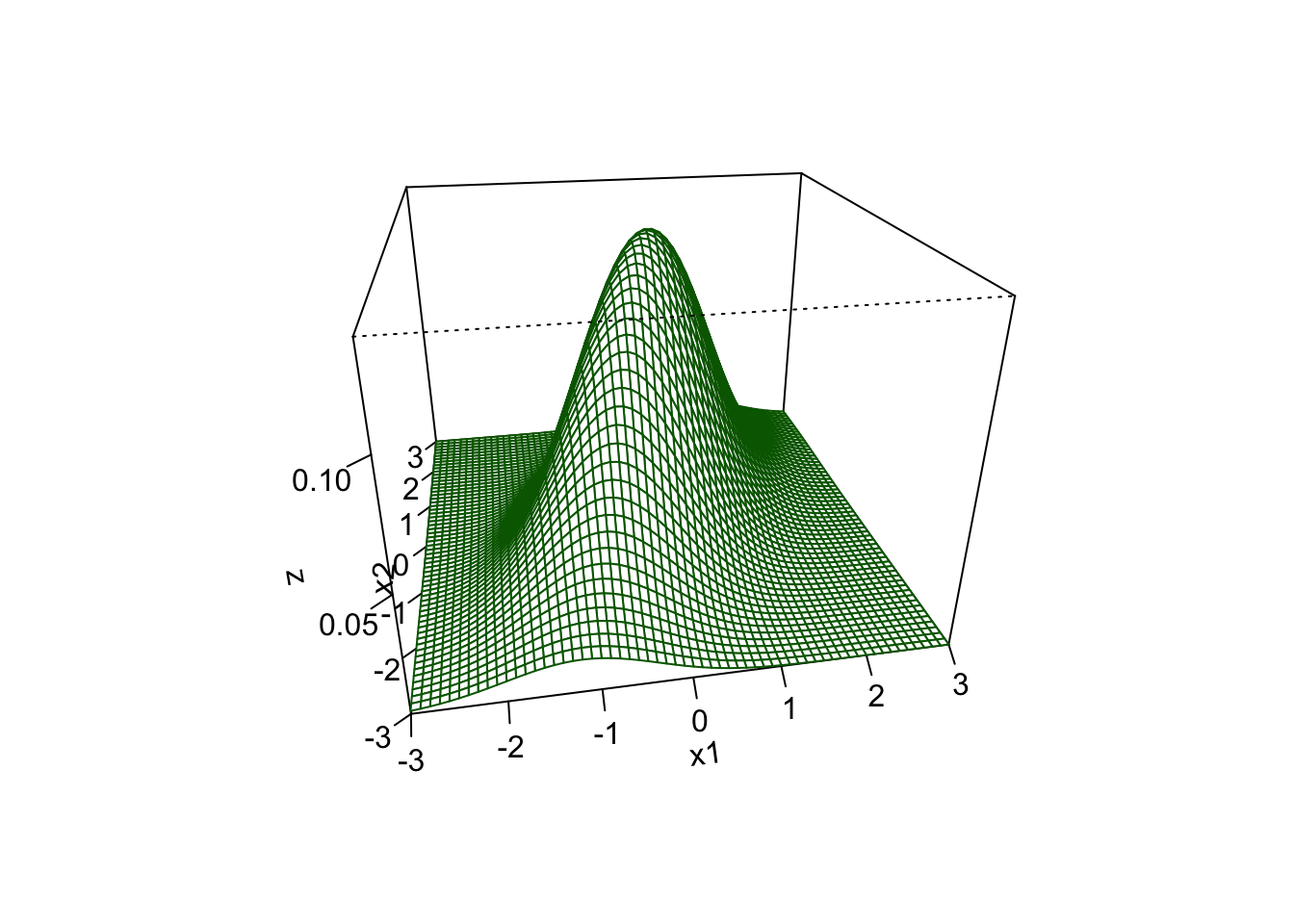
A.8.2 Definition of a Multivariate Normal Distribution
A random vector \(\vec{X}\) has a multivariate normal distribution if its probability density function (pdf) is given by:
\[ f(\vec{X}) = \frac{1}{(2\pi)^{k/2}|\Sigma|^{1/2}} e^{-\frac{1}{2}(\vec{X} - \vec{\mu})^\intercal \Sigma^{-1}(\vec{X}-\vec{\mu})} \tag{A.2}\]
where: \(\vec{\mu} = E[\vec{X}], \quad \Sigma = Cov(\vec{X})_{k \times k}\) and \(|\Sigma|\) denotes the determinant of \(det(\Sigma)\).
The joint Normal distribution of \(\vec{X}\) is denoted by \(\vec{X} \sim N_k(\vec{\mu},\Sigma)\).
A.8.3 Properties
- If \(\vec{X} \sim N_k(\vec{\mu},\Sigma)\), then the marginal distribution of \(X_i\) is \(\sim N(\mu_i, \sigma^2_i)\).
- If \(Cor(x_i, x_j)=0 \text{ for all } i \neq j\) then
\[ \Sigma = \begin{bmatrix} \sigma^2_1 & 0 & \cdots&0\\ 0&\sigma^2_2 & \cdots&0 \\ \vdots & \vdots & \cdots & \vdots \\ 0 & 0 & \cdots & \sigma^2_k \end{bmatrix} \]
and \(x_1, \dotsc, x_k\) are independent normally-distributed random variables.
A.9 Matrices and the Classic Multiple Linear Regression Model
Let there be \(p-1\) predictor/explanatory variables \(X_1, \dotsc, X_{p-1}\).
Assume the true model is:
\[Y_i = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \cdots + \beta_{p-1} X_{i,p-1} + \epsilon_i \quad i=1, \dotsc, n \tag{A.3}\]
The Equation A.3 model can also be written as a set of \(n\) equations:
\[\begin{align}Y_1 & = \beta_0 + \beta_1 X_{11} + \beta_2 X_{12} + \cdots + \beta_{p-1} X_{1,p-1} + \epsilon_1\\ Y_2 & = \beta_0 + \beta_1 X_{21} + \beta_2 X_{22} + \cdots + \beta_{p-1} X_{2,p-1} + \epsilon_2\\ Y_3 & = \beta_0 + \beta_1 X_{31} + \beta_2 X_{32} + \cdots + \beta_{p-1} X_{3,p-1} + \epsilon_3\\ \vdots\,\,\, & = \qquad \qquad \qquad \qquad \vdots \\Y_n & = \beta_0 + \beta_1 X_{n1} + \beta_2 X_{n2} + \cdots + \beta_{p-1} X_{n,p-1} + \epsilon_n\\ \end{align}\]
One can then convert the \(n\) equations into a new form based on four matrices:
\[\text{Let }\vec{Y}_{n \times 1} = \begin{bmatrix}Y_1\\ Y_2\\ Y_3\\\vdots\\ Y_{n}\end{bmatrix} \quad \text{ and } \quad\vec{\epsilon}_{n \times 1} = \begin{bmatrix}\epsilon_1\\ \epsilon_2\\ \epsilon_3\\ \vdots\\ \epsilon_n\end{bmatrix} \tag{A.4}\]
Then define
\[X_{n \times p} = \begin{bmatrix}1 & X_{11} & X_{12} & \cdots & X_{1,p-1} \\1 & X_{21} & X_{22} & \cdots & X_{2,p-1} \\1 & X_{31} & X_{32} & \cdots & X_{3,p-1} \\\vdots & \vdots & \vdots & \cdots & \vdots \\1 & X_{n1} & X_{n2} & \cdots & X_{n,p-1} \\\end{bmatrix} \quad \text{ and } \quad \vec{\beta}_{p\times 1} = \begin{bmatrix}\beta_0\\ \beta_1\\ \beta_2\\ \vdots\\ \beta_{p-1}\end{bmatrix} \tag{A.5}\]
One can combine Equation A.4 and Equation A.5 to get the matrix form of the true model:
\[\vec{Y}_{n\times 1} = X_{n \times p}\vec{\beta}_{p \times 1} + \vec{\epsilon}_{n \times 1} \tag{A.6}\]
Note
The multiplication of \(X\vec{\beta}\) results in an \((n \times 1)\) matrix (a column vector).
In the Equation A.6 form of the linear model, the matrix \(X\) is called the design matrix.
A.10 A Geometric Perspective on Matrices and Matrix Operations
The previous sections discuss matrices from an analytical perspective. This section will look at matrices from a geometric perspective. This is based heavily on ideas and content in the YouTube series by 3Blue1Brown called Essence of linear algebra.
A.11 Vectors, Points, Spans, and Bases in \(\mathbb{R}^n\)
A.11.1 Vectors with One Element: \(\mathbb{R}^1\)
Given a vector with one element: \(\vec{v} = \begin{bmatrix} 2 \end{bmatrix}\), this can be thought of as representing a point on a 1-Dimensional number line ranging from \(-\infty \leftarrow 0 \rightarrow \infty\) where the element value is the distance from 0.
We can multiply this vector by any scalar value and get another value on the number line.
This is known as scaling the vector.
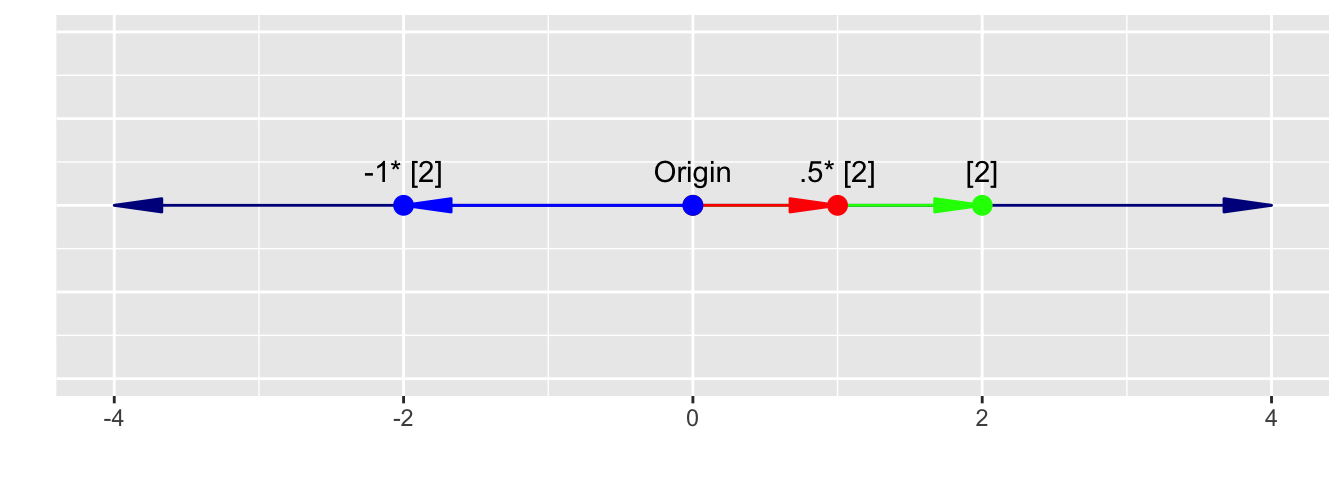
A.11.1.1 The 1-d Unit Vector
We can represent any point on the number line by scaling a vector of length 1, \(\hat{i}\) (known as the unit vector), by the appropriate scalar \(a\).
The red vector in Figure A.2 above is a unit vector \(\hat{i} = \begin{bmatrix} 1 \end{bmatrix}\)
A.11.1.2 Linear Combinations of 1-d Vectors
We can also create linear combinations of 1-d vectors by adding them together.
\[ \begin{align} \begin{bmatrix}4 \end{bmatrix} + \begin{bmatrix}-2 \end{bmatrix} &= \begin{bmatrix}2 \end{bmatrix} \\ \\ \begin{bmatrix}4 \end{bmatrix} + \begin{bmatrix}-2 \end{bmatrix}&= 4\hat{i} + (-2)\hat{i}= 2\hat{i} = 2\begin{bmatrix}1 \end{bmatrix} \end{align} \]
ImportantSpan of a Vector and Basis Vectors
The set of all linear combinations of a vector, say \(\hat{i}\), is known as the span of the vector.
In 1-d, the span of \(\hat{i}\) includes every point on the number line. We don’t need any other vector to find a point.
Thus \(\hat{i}\) is known as a generator for the 1-d vector space.
Since there is only 1 vector, \(\hat{i}\), in the set of generators for 1-d space, we do not have to check if it is independent of other vectors.
The set of vectors \(S\) that are linearly independent and generate the space (their span includes every point in the space) is known as the basis for the space. The member vectors of \(S\) are the basis vectors for the space.
Here, \(\hat{i}\) is a basis vector for the 1-d vector space.
NoteVector Space
A vector space of dimension \(d\) is a subset of possible values for a geometric object of \(d\) dimensions that passes through the origin which has the following properties.
- One can do addition and scalar-multiplication operations
- Those operations are commutative and distributive
- The subset contains the zero vector 0 (the origin).
- If the subset contains \(\vec{v}\) then it contains \(a\vec{v}\) for every scalar \(a\).
- If subset contains \(\vec{u}\) and \(\vec{v}\), then it contains \(\vec{u} + \vec{v}\).
A.11.2 Vectors with Two Elements:\(\mathbb{R}^2\)
Let’s consider a vector with two elements: \(\vec{v} = \begin{bmatrix} 2 \\ 3 \end{bmatrix}\).
With two elements, this can be thought of as representing a point on a 2-dimensional \(x, y\) plane where both \(x\) and \(y\) have the range \(-\infty \leftarrow 0 \rightarrow \infty\).
- The element values are the distance from 0 in the \(x\) direction and then the \(y\) direction.
- We use the following notation to denote the \(x\) and \(y\) elements of the 2 dimensional vector.
\[\vec{v} = \begin{bmatrix} x \\ y\end{bmatrix}\] - The point \((0,0)\) is called the origin. - We will think of all vectors as being expressed geometrically as an arrow with the tail at the origin and head at the point away from the origin.
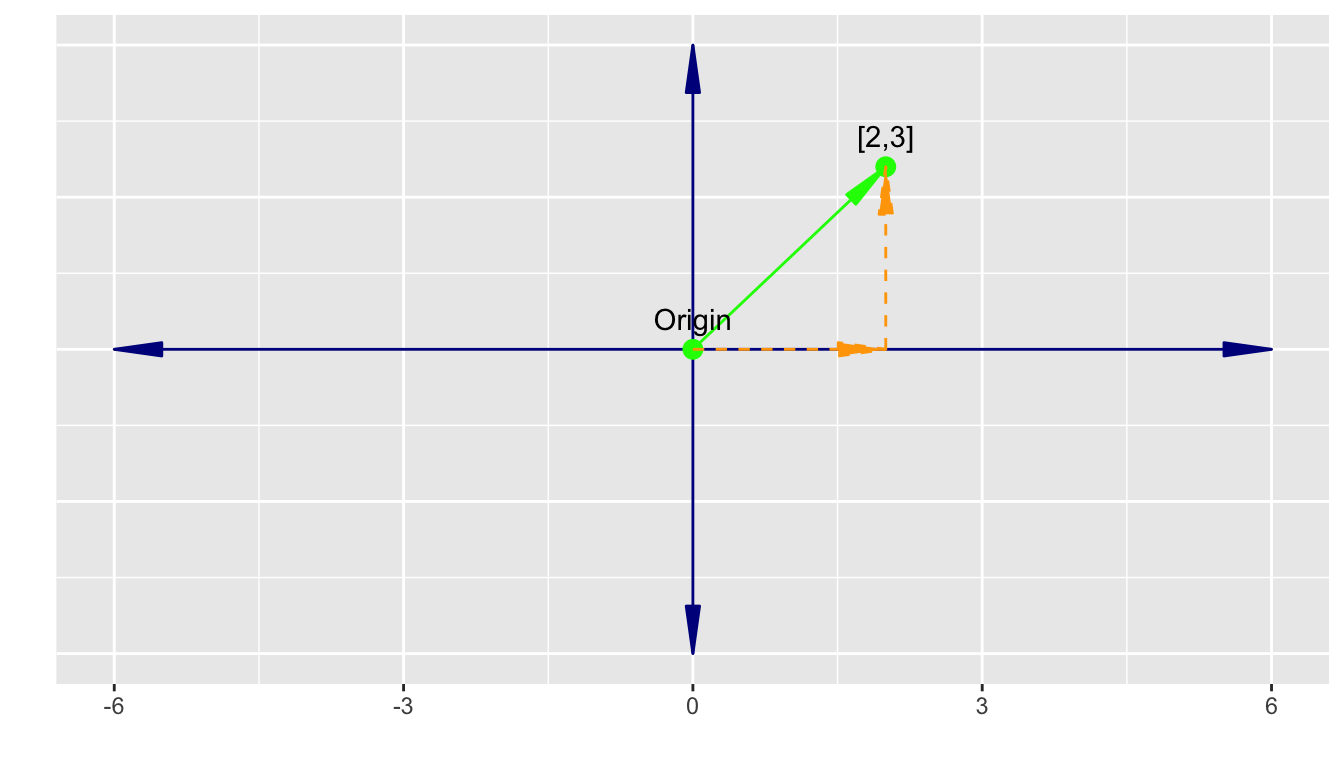
We can still scale a two dimensional vector by multiplying it by a scalar.
Important
However, we cannot create every point in the 2-d space with one vector, only those points in the span of the original vector.
A single vector does not have a span that generates a 2-d space.
To generate the 2-d space, we need a second vector that is not in the span of the first vector.
A.11.2.1 Unit Vectors in 2-d
Let’s define two unit vectors, \(\vec{v}_i\) in the \(x\) direction, and \(\vec{v}_j\) in the \(y\) direction.
\[\vec{v}_i = \begin{bmatrix}1\\ 0 \end{bmatrix} \text{ and }\vec{v}_j \begin{bmatrix}0 \\1 \end{bmatrix}\]
A.11.2.2 Scaling and Vector Addition in 2-d
We can consider the vector \(\vec{v} = \begin{bmatrix} 2 \\ 3 \end{bmatrix}\) as representing scalar multiplication of two unit vectors, \(\vec{v}_i\) in the \(x\) direction and \(\vec{v}_j\) in the \(y\) direction, followed by their addition.
\[\vec{v} = \begin{bmatrix} 2 \\ 3 \end{bmatrix} = 2\vec{v}_i + 3 \vec{v}_j = 2\begin{bmatrix} 1 \\ 0 \end{bmatrix} + 3\begin{bmatrix} 0 \\ 1 \end{bmatrix}\]
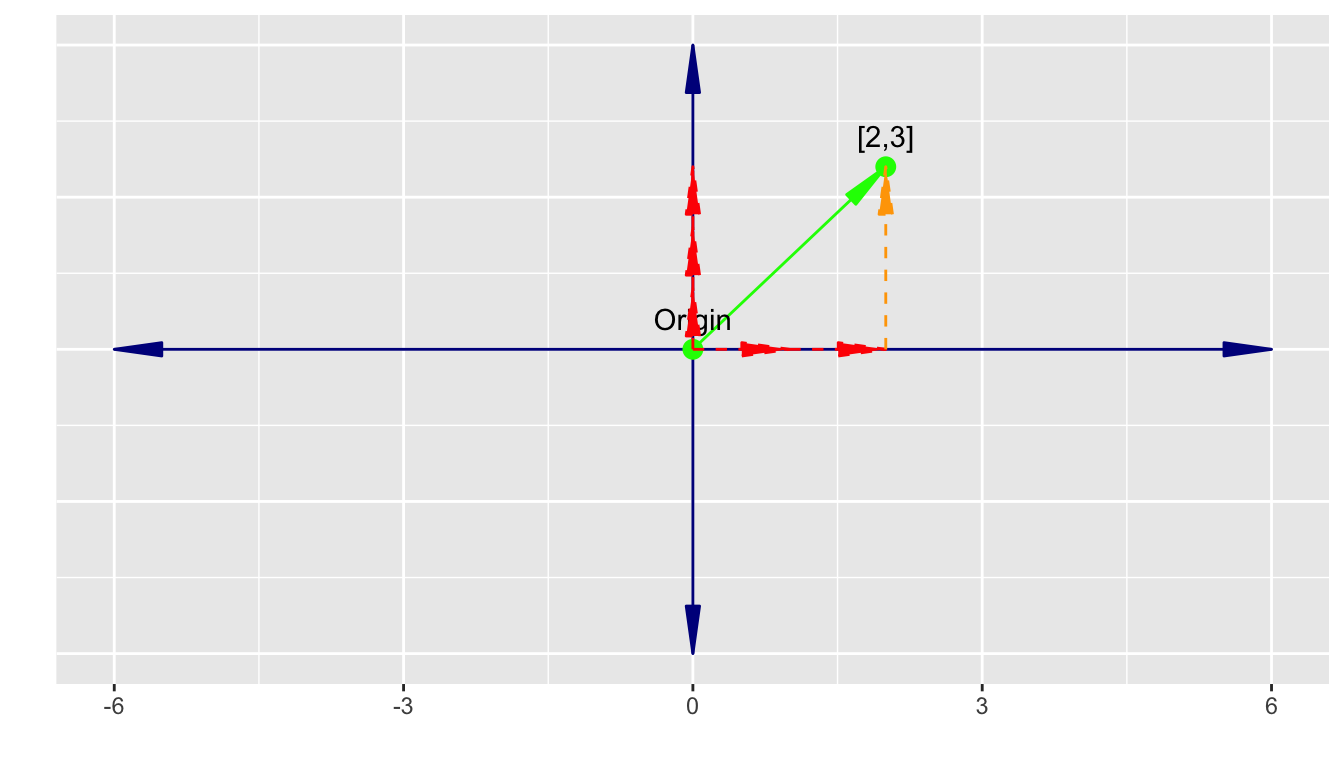
The orange line in Figure A.4 represents the addition of two vectors as discussed in Section A.3.2.
Geometrically, it can be seen as moving the tail of the second vector to the head of the first vector. Their sum is the new location of the head of the second vector.
Let’s add \(\vec{v} = \begin{bmatrix} 2 \\ 3 \end{bmatrix} + \vec{v} = \begin{bmatrix} -3 \\ 1 \end{bmatrix}\).
- We plot the two vectors with tails at the origin and then move the second (red) vector so its tail is at the head of the first vector.
- The result is the head of the shifted second vector, here
\[\vec{v} = \begin{bmatrix} 2 \\ 3 \end{bmatrix} + \begin{bmatrix} -3 \\ 1 \end{bmatrix} = \begin{bmatrix} -1 \\ 4 \end{bmatrix}\].
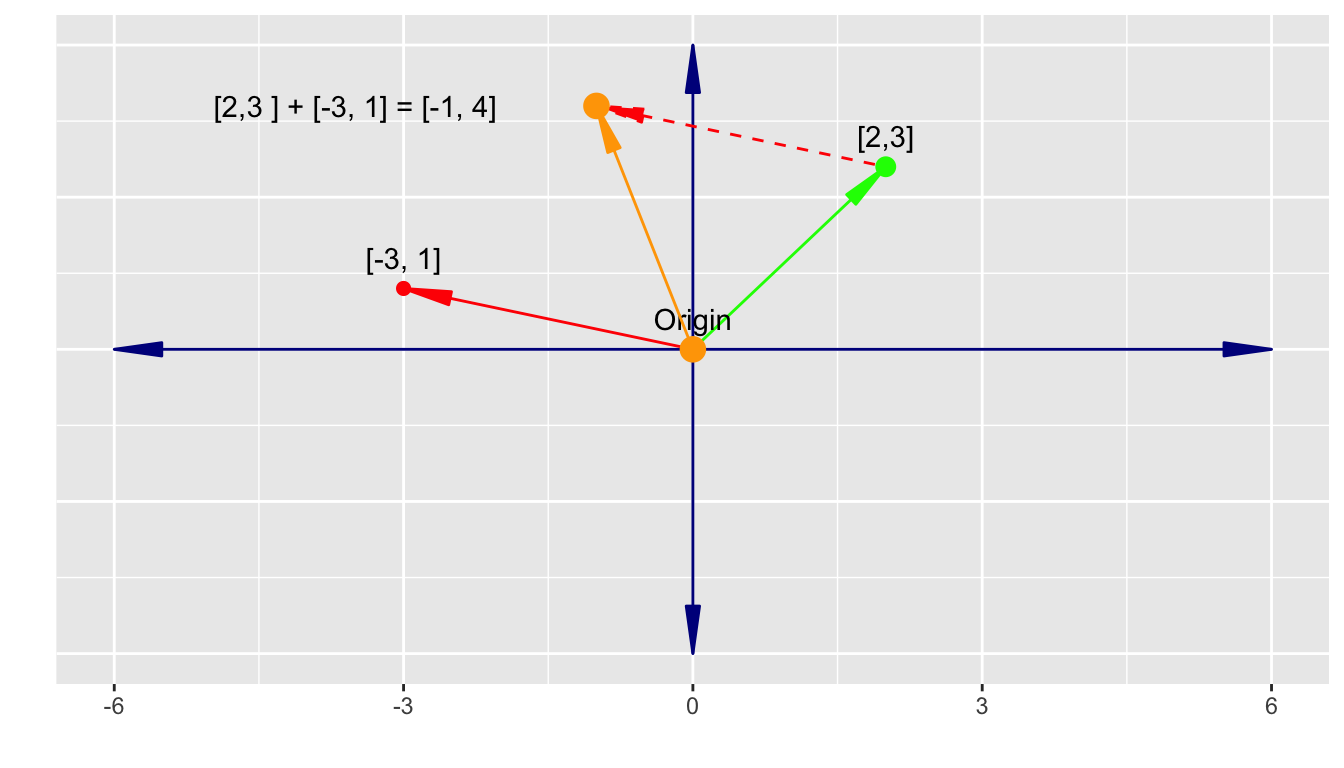
A.11.2.3 Linear Combinations and Linear Independence
With two 2-d vectors, \(\vec{u}\) and \(\vec{v}\), we can use scaling and vector addition to create a new vector \(\vec{w}\) that is a linear combination of \(\vec{u}\) and \(\vec{v}\), such that
\[ a\vec{u} + b \vec{v} = \vec{w} \]
NoteEvery vector space contains the origin.
If \(a=b=0\) in \(a\vec{u} + b \vec{v} = \vec{w}\), then \(\vec{w}\) is the origin.
Assuming \(a, b \neq 0\), then we say \(\vec{u}\) and \(\vec{v}\) are linearly dependent if we can choose \(a\) and \(b\) such that \(a\vec{u} + b \vec{v} = 0\).
Important
If two vectors are linearly dependent, it means they share the same span. Thus the dimension of the span of the set \(\{\vec{u}, \vec{v}\}\) is 1, not 2.
Consider \(\vec{u} = \begin{bmatrix}2 \\3\end{bmatrix}\) and \(\vec{v} = \begin{bmatrix}-1 \\-1.5\end{bmatrix}\).
- We can find scalars \(a = 1, b = 2\) such that \(a\vec{u} + b \vec{v} =\vec{0}\).
\[ a\begin{bmatrix}2 \\3\end{bmatrix} + b\begin{bmatrix}-1\\ -1.5\end{bmatrix} \implies \begin{bmatrix}2 \\3\end{bmatrix} + 2 \begin{bmatrix}-1\\ -1.5\end{bmatrix} = \begin{bmatrix}0\\ 0\end{bmatrix} \]
- Thus \(\vec{u}\) and \(\vec{v}\) are linearly dependent and share the same span as seen here.
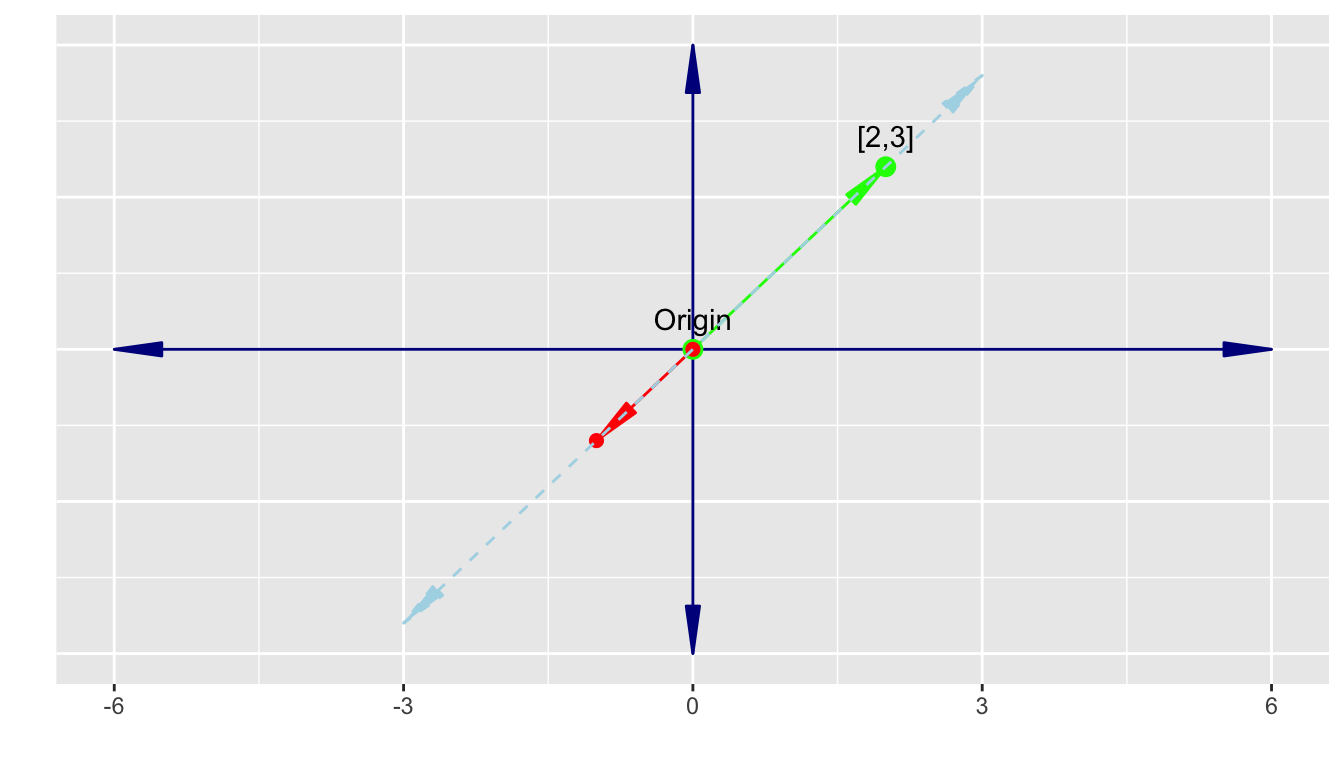
Reducing the span by one dimension from 2-1 is equivalent to converting the vector space from a 2-d plane to a 1-d number line.
To generate a 2-d space, we need a second vector that is not in the span of the first vector i.e., is linearly independent of the first vector.
The unit vectors \(\hat{i}\) and \(\hat{j}\) are linearly independent.
Thus the set \(S = \{\hat{i},\hat{j}\}\) has dimension 2 and can generate the 2-d space.
The set \(S = \hat{i},\hat{j}\) are a basis for the 2-d space.
A.11.2.4 Basis Vectors
Is the set \(S = \hat{i},\hat{j}\) the only set of basis vectors in 2-d space? No.
Any set of two linearly independent vectors \(\vec{u}\) and \(\vec{v}\), such as \(\vec{u}= \begin{bmatrix}2 \\3\end{bmatrix}\) and \(\vec{v} = \begin{bmatrix}-1 \\3\end{bmatrix}\), can serve as the basis.
- The vectors do not even have to be orthogonal.
Changing the basis is equivalent to changing the reference coordinate system for the space.
- Any time we interpret the values of the elements in a vector, we are implicitly using the bases vectors to shape our interpretation.
Thus we normally assume we are using \(S = \hat{i},\hat{j}\) as the basis since it corresponds to the 2-d Cartesian plane with \(x\) as the horizontal axis and \(y\) as the vertical axis.
A.11.3 Three dimensions and Higher: \(\mathbb{R}^n\)
The same concepts from \(\mathbb{R}^1\) and \(\mathbb{R}^2\) apply as we move into higher dimensions.
A.11.3.1 Vector Elements
For three dimensions \(\mathbb{R}^3\), a vector now has three elements \(\vec{u} = \begin{bmatrix} x \\ y \\ z \end{bmatrix}\)
For \(n\) dimensions, a vector has \(n\) elements \(\vec{x} = \begin{bmatrix} x_1 \\ \vdots\\ x_n \end{bmatrix}\).
A.11.3.2 Span and Bases in \(\mathbb{R}^n\)
With two linearly independent vectors in 3-d vector space, their span is still in 2-d space.
- In 3-d space, graphing the result of every linear combination of 2 linearly independent vectors, e.g., \(a\hat{i} + b\hat{j} = \vec{w}\), creates a 2-d plane in 3-d space, centered on the origin.
- In \(\mathbb{R}^n\), the result of every linear combination of \((n-1)\) linearly independent vectors \(a_1 \vec{x}_1 + a_2\vec{x_2} + \cdots + a_{(n-1)}\vec{x}_{n-1}= \vec{w}_{n-1}\) creates an \((n-1)\)-dimensional hyper-plane in \(\mathbb{R}^n\) space, centered on the origin.
If we add a third vector in \(\mathbb{R}^3\) we can add vectors as before.
- Add the first two vectors by moving the tail of the second to the head of the first.
- Then, move the tail of the third vector to the head of the second.
- The new location of the head of the third vector is the result.
This is equivalent to:
\[\text{Given }\vec{u} = \begin{bmatrix} x_1 \\ y_1\\ z_1 \end{bmatrix} \quad\vec{v} = \begin{bmatrix} x_2 \\ y_2\\ z_2 \end{bmatrix} \quad\vec{w} = \begin{bmatrix} x_3 \\ y_3\\ z_3 \end{bmatrix}\]
\[\text{Vector addition }\\\vec{u} + \vec{v} + \vec{w} = \begin{bmatrix} x_1 + x_2 \\ y_1 +y_2 \\z_1 + z_2 \end{bmatrix}+ \begin{bmatrix} x_3 \\ y_3\\ z_3\end{bmatrix} = \begin{bmatrix} x_1 + x_2 + x_3 \\ y_1 +y_2 + y_3\\z_1 + z_2 +z_3\end{bmatrix} = \vec{w}\]
The span of the three 3-d vectors is the set \(S\) of all possible linear combinations of \(a\vec{u} + b\vec{v} + c\vec{w}\).
- The dimension of the \(S\) is the number of linearly independent vectors in \(S\).
- If one or more of the vectors in \(S\) is linearly dependent on one or more of the others, (it is in the span of one or their linear combination), the dimension of set \(S\) is still the number of linearly independent vectors in \(S\), so may be 1 or 2.
- If the three vectors are all linearly independent of each other, the span of \(S\) has dimension 3, the three vectors can generate \(\mathbb{R}^3\), and the set \(S\) can serve as a basis for \(\mathbb{R}^3\).
- This can be thought of as taking the span of the first two vectors (a horizontal \(x, y\) plane) and using the third vector to move it from \(-\infty \rightarrow \infty\) in the \(z\) dimension.
In \(\mathbb{R}^n\), the span of \(n\), \(n\)-dimensional vectors is the set \(S\) of all possible linear combinations of \(a_1\vec{x_1} + a_2\vec{x_2} +\cdots + a_n\vec{x_n}\).
- The dimension of a set of vectors \(S\) is the number of linearly independent vectors in \(S\).
- If one or more of the vectors in \(S\) is linearly dependent on one or more of the others, (it is in the span of one or a linear combination of others), the dimension of set \(S\) is still the number of linearly independent vectors in \(S\), so may from range from 1 to \(n-1\).
- If the \(n\) vectors are all linearly independent of each other, the span of \(S\) has dimension \(n\), the \(n\) vectors can generate \(\mathbb{R}^n\), and the set \(S\) can serve as a basis for \(\mathbb{R}^n\).
In \(\mathbb{R}^n\), consider the set of \(n\) unit vectors along each axis as the basis for the \(\mathbb{R}^n\). This helps with the interpretation of matrices as linear transformations of a vector in \(\mathbb{R}^n\).
A.12 Matrices as Linear Transformations of Vectors
A.12.1 Linear Transformations in General
A transformation is a function that maps an input value to an output value.
We are interested in using a function to map a vector to a different vector in \(\mathbb{R}^n\).
- The function can be considered the rules for reshaping and moving the input vector to look like the output vector.
- This is equivalent to applying a function to a point in \(\mathbb{R}^n\) to produce another point in \(\mathbb{R}^n\).
To make the transformation linear, we have to add two constraints to the function.
- It must preserve the linearity of lines - all input lines must be output as lines.
- The origin must not be shifted.
These are equivalent to transformations that keep all the gird lines on the plan as parallel and evenly spaced.
Important
A linear transformation of any \(n\) dimensional vector can be described as a linear combination of the unit vectors in the basis for \(\mathbb{R}^n\).
An example in \(\mathbb{R}^2\).
- Start with a vector \(\vec{u} = \begin{bmatrix} -1 \\2\end{bmatrix} = -1 \hat{i} + 2 \hat{j}\)
If we use transformation that moves the vector to \(\vec{v}\), it preserves the coefficients of the linear combination and we just have to think about what happens to the \(\hat{i}\) and \(\hat{j}\).
\[\vec{v} = -1 (\text{transformed } \hat{i}) + 2(\text{transformed }\hat{j})\]
If our transformation moved \(\hat{i}\) to \(\begin{bmatrix} 1 \\-2\end{bmatrix}\) and \(\hat{j}\) to \(\begin{bmatrix} 3 \\0\end{bmatrix}\), then the final vector will be
\[\vec{v} = -1\begin{bmatrix} \,\,\,1 \\-2\end{bmatrix} + 2\begin{bmatrix} 3 \\0\end{bmatrix} = \begin{bmatrix} 5\\2\end{bmatrix}\]
We can write this transformation in terms of any input as
\[\vec{u} = \begin{bmatrix} x \\y\end{bmatrix} \text{transformed }\rightarrow x\begin{bmatrix} 1 \\2\end{bmatrix} + y\begin{bmatrix} 3 \\0\end{bmatrix}= \begin{bmatrix} 1x+ 3y \\-2x + 0y\end{bmatrix}\]
We can make this even more general.
ImportantLinear Transformations in \(\mathbb{R}^2\).
We can describe any linear transformation in \(\mathbb{R}^2\) using just 4 numbers.
- Two for the vector where \(\hat{i}\) lands after the transformation and
- Two for the vector where \(\hat{j}\) lands after the transformation.
We combine these four numbers (two vectors) into a 2x2 matrix as
\[\begin{bmatrix} x_{\hat{i}} \,\, x_{\hat{j}} \\y_{\hat{i}} \,\, y_{\hat{j}}\end{bmatrix}\]
Where the first column describes the new location of \(\hat{i}\) and the second column in the new location of \(\hat{j}\).
So, to apply a transformation matrix to any vector in \(\mathbb{R}^2\), we use the elements in the input vector to create a linear combination of the vectors in the transformation matrix.
Given a 2x2 matrix \(\begin{bmatrix} \,\,\,3\quad \,2 \\-2\quad 1\end{bmatrix}\), if we want to transform \(\begin{bmatrix} 5 \\7\end{bmatrix}\), the linear combination looks like:
\[\begin{bmatrix} \,\,\,3\quad \,2 \\-2\quad 1\end{bmatrix} \quad \begin{bmatrix} 5 \\7\end{bmatrix} = 5\begin{bmatrix} 3\\ 2\end{bmatrix} + 7 \begin{bmatrix} 2\\ 1\end{bmatrix} =\begin{bmatrix} 29\\ 17\end{bmatrix}\]
Or in general.
\[\begin{bmatrix} a\quad b \\c\quad d\end{bmatrix} \quad \begin{bmatrix} x \\y\end{bmatrix} = x\begin{bmatrix} a\\c\end{bmatrix} + y \begin{bmatrix} b\\ d\end{bmatrix} =\begin{bmatrix} ax + by\\ cx + dy\end{bmatrix}\]
Note
Putting the matrix on the left of the vector is equivalent to using \(f(\vec{v}) = \vec{w}\) where \(f()\) is a transformation function.
We have previously seen \(f()\) as the function for matrix multiplication in Section A.3.4.
A square matrix of size \(n\) can thus be interpreted as just a function to make a linear transformation of a vector in \(\mathbb{R}^n\).
- The linear transformation is completely described by \(n^2\) numbers which describe the new locations of the unit vectors in the basis of the space.
- We can put these numbers into the columns of a square matrix to describe where each of the \(n\) unit vectors winds up after the transformation.
- Matrix multiplication can be interpreted as reshaping the space to move the input vector into a new position in \(\mathbb{R}^n\).
A.12.2 Executing Multiple Transformations
We often want to execute a sequence of transformations, sometimes called creating a composition of transformations.
This is equivalent to multiplying multiple matrices.
Since each multiplication results in a new matrix describing where each of the \(n\) unit vectors winds up after the transformation, we can just repeat the process.
Note
When multiplying a vector by two matrices, we write it in the form from left to right as
\[\begin{bmatrix} e\quad f \\g\quad h\end{bmatrix} \begin{bmatrix} a\quad b \\c\quad d\end{bmatrix} \quad \begin{bmatrix}x \\y\end{bmatrix}\]
where we execute as \(g(f(\vec{X}))\)
\[\begin{bmatrix} e\quad f \\g\quad h\end{bmatrix} \, \left(\begin{bmatrix} a\quad b \\c\quad d\end{bmatrix} \begin{bmatrix} x \\y\end{bmatrix}\right)\]
As noted in Section A.3.4.3, compositions of matrix transformations (multiple multiplications) are not commutative.
That means, that except for special cases,
\[\begin{bmatrix} e\quad f \\g\quad h\end{bmatrix} \, \left(\begin{bmatrix} a\quad b \\c\quad d\end{bmatrix} \begin{bmatrix} x \\y\end{bmatrix}\right) \neq \begin{bmatrix} a\quad b \\c\quad d\end{bmatrix} \left(\begin{bmatrix}e\quad f \\g\quad h\end{bmatrix} \, \begin{bmatrix} x \\y\end{bmatrix}\right)\]
A.12.3 Determinants
These linear transformations by matrices are reshaping the space of the input vector.
This means they are often either stretching the space or shrinking the space, with or without some rotations in one or more dimensions.
In \(\mathbb{R}^2\), we are often then interested in by what factor does a transformation change the area of a space.
Consider the transformation matrix \(\begin{bmatrix} 3\quad 0 \\0\quad 2\end{bmatrix}\).
- It scales \(\hat{i}\) by a factor of 3 and \(\hat{j}\) by a factor of 2.
- This means that the 1 x 1 square formed by \(\hat{i}\) and \(\hat{j}\) now is a 3 x 2 rectangle so has an area of 6.
- We can say this linear transformation scaled the area by a factor of 6.
Now, consider a linear transformation known as a shear transformation.
- It has the transformation matrix \(\begin{bmatrix} 1\quad 1 \\0\quad 1\end{bmatrix}\)
- This leaves \(\hat{i}\) in place but moves \(\hat{j}\) over to \((1, 1)\).
- This means the 1 x 1 square is now a parallelogram but it still has area 1.
This scaling factor of a linear transformation matrix is called the determinant of the transformation matrix as seen back in Section A.2.1.1.
This scaling factor applies to any area defined by vectors in \(\mathbb{R}^2\).
For \(\mathbb{R}^n\), the matrix will scale the volumes instead of the area.
For \(\mathbb{R}^n3\), it is the volume of the parallelepiped created by the three unit vectors along each axis.
If \(A\) is a transformation matrix with determinant 3, it scales up all the areas by a factor of 3.
If \(B\) is a transformation matrix with determinant 1/2, it shrinks down all the areas by a factor of 1/2.
ImportantDeterminant of 0
If a 2-d transformation matrix has a determinant of 0, it shrinks all of the space into a 1-d line or even a single point (0,0).
This is equivalent to the columns of the matrix being linearly dependent.
This can be useful as we will see later on to simplify the representation of a transformation as a matrix.
What does it mean to have a determinant that is \(<0\)?
- This is known as a transformation that flips the coordinate reference system or “invert the orientation of space”.
- This can also be visualized as \(\hat{i}\) moving from the usual position to the right of \(\hat{j}\) to now being on the left of \(\hat{j}\).
- The Absolute Value of the determinant still shows how much the areas have been scaled (increased or shrunk down).
- In \(\mathbb{R}^3\), this means the orientation has been inverted from a “right hand rule” to a “left-hand rule”.
To take a general view, consider the matrix \(A = \begin{bmatrix} a\quad b \\c\quad d\end{bmatrix}\) where
\[\text{det}(A) = \text{det}\left(\begin{bmatrix} a\quad b \\c\quad d\end{bmatrix}\right) = ad -bc\]
If \(b=c=0\) then there then \(A\) is the diagonal matrix \(A = \begin{bmatrix} a\quad 0 \\0\quad d\end{bmatrix}\).
- The transformation creates a new rectangle out of the unit vector 1x1 square as seen in Figure A.7.
- \(a\) is the factor for how much \(\hat{i}\) is stretched.
- \(b\) is the factor for how much \(\hat{j}\) is stretched
- \(ab\) is the area of the new rectangle compared to the original 1x1 square.
If either \(b\) or \(c\) is non-zero, then,
- The transformation creates a new parallelogram out of the unit vector 1x1 square as seen in Figure A.8.
- \(ab\) is still the area of the new parallelogram, with base \(a\) and height \(b\), compared to the original 1x1 square.
If \(b\) and \(c\) are both non-zero, then,
- The transformation creates a new parallelogram out of the unit vector 1x1 square and stretches (shrinks) it in the diagonal direction.
Note
When multiplying two matrices, \(A\) and \(B\), \(\text{det}(AB) = \text{det}(A)\text{det}(B)\)
A.13 Matrices and Systems of Linear Equations
A system of linear equations is a set of equations that describes the relationships among \(n\) variables through scaling the variables and adding then together to create a result.
We want to solve the system of linear equations and transformation matrices can help us do that.
If you have a system of linear equations you can organize it with all of the variables and their coefficients on the left and all of the results (scalars) on the right of the equal sign.
- You may need to make \(0\) or \(1\) coefficients explicit so you have the same number of coefficients in each equation.
Now, convert the system of equations into matrix form by converting the variables and results to vectors and the coefficients into a matrix.
\[\begin{align}2x + 5y + 3z &= -3\\4x + 0y + 8z & = 0 \\1x + 3y + 0z & = 2\end{align} \rightarrow\begin{bmatrix}2\quad 5 \quad 3\\4\quad 0\quad8\\1\quad3\quad0\end{bmatrix} \overbrace{\begin{bmatrix}x\\y\\z\end{bmatrix}}^{\text{Variables}} =\begin{bmatrix}-3\\0\\2\end{bmatrix}\]
We can label each part as follows
\[\begin{align}2x + 5y + 3z &= -3\\4x + 0y + 8z & = 0 \\ 1x + 3y + 0z & = 2\end{align} \rightarrow\overbrace{\begin{bmatrix} 2\quad 5 \quad 3\\ 4\quad 0\quad 8\\ 1\quad3\quad0 \end{bmatrix}}^A \overbrace{\begin{bmatrix} x\\y\\z \end{bmatrix}}^{\vec{x}} = \overbrace{\begin{bmatrix} -3\\0\\2 \end{bmatrix}}^{\vec{v}}\]
and now rewrite in matrix vector form:
\[A\vec{x} = \vec{v} \tag{A.7}\]
We can interpret the system of equations then as a matrix transformation (or function) of the input vector \(\vec{x}\) that results in the vector \(\vec{v}\).
Our interest is in figuring out what input vector \(\vec{x}\), when the space is scaled and squished by \(A\), now looks like \(\vec{v}\).
There are two cases
- The matrix \(A\) squishes the space down by a dimension, i.e., \(\text{det}(A) = 0\)
- The matrix \(A\) squishes the space in a way that preserves the dimension of the space, i.e., \(\text{det}(A) \neq 0\)
A.13.0.1 Solutions with \(\text{det}(A) \neq 0\)
When \(\text{det}(A) \neq 0\), there where always be one, and only one, \(\vec{x}\) such that \(A\vec{x} = \vec{v}\).
We can find this by reversing the transformation. This reverse of the transformation is its own transformation matrix which is called the inverse of \(A\) or \(A^{-1}\).
As an example, if \(A\) were a counterclockwise rotation of \(90^\circ\), \(\begin{bmatrix}0 \quad -1 \\1 \quad \quad0\end{bmatrix}\) then,
\(A^{-1}\) would be the matrix of a clockwise rotation of \(90^\circ\), \(\begin{bmatrix}\quad0 \quad 1 \\-1 \quad 0\end{bmatrix}\).
So in case 2, where \(A^{-1}\) exists, like with functions where \(f^{-1}f(x) = x\), you wind up where you started.
\[A^{-1}A\vec{x} = \vec{x} \qquad \text{ and } \qquad A^{-1}A = I = \begin{bmatrix}1\quad 0 \\0 \quad 1\end{bmatrix}\]
Now we can solve for \(\vec{x}\) by multiplying both sides of Equation A.7 by \(A^{-1}\) to get
\[A^{-1}A\vec{x} = A^{-1}\vec{v} \implies \vec{x} = A^{-1}\vec{v} \]
This can be interpreted as using \(\vec{v}\) as the input vector and shifting its space using \(A^{-1}\) to see what vector is the output, the \(\vec{x}\) of interest.
A.13.0.2 Solutions with \(\text{det}(A) = 0\)
When the system of equations has a transformation matrix \(A\) with \(\text{det}(A) = 0\), then the matrix squishes the space down into a volume of 0, effectively dropping the dimension of the space by one.
- \(\text{det}(A) = 0 \implies \nexists A^{-1}\)
However, there can still be a solution to the system of equations if the solution exists in the lower dimensional space.
As an example, if a 2-d matrix squishes down to a line, it could be true that \(\hat{v}\) is in the span of that line.
In \(\mathbb{R}^3\), it is also possible for a solution to exist if \(A\) squishes down the solution space by 2 dimensions to a plane or even 1 dimension to a line.
- It would much hard to find a solution for the single line than for the plane even though both have \(\text{det}(A) = 0\).
To differentiate the different types of output in higher dimensions, we use the term Rank.
- If the transformation matrix has an output of 1-d, the matrix has Rank = 1.
- If the transformation matrix has an output of 2-d, the matrix has Rank = 2.
- and so on.
The set of all possible outputs of \(A\vec{v}\) is called the Column Space of \(A\).
- You can think about it as the number of columns in \(A\) where each represents the effect on the unit vectors.
- The span of these vectors is all possible outputs, which by definition is the column space.
- So, Rank is also the number of dimensions of the column space.
- If a matrix has a Rank = the number of columns, which is as high as it could be, the matrix has Full Rank.
If a matrix has full rank, then the only vector that transforms to the origin is the 0 vector.
If a matrix has less than full rank, so it squishes down to a smaller dimension, then you can have a lot of vectors that transform to 0.
If a 2-d matrix squishes to a line, there is a second line, in a different direction, where all the vectors on the second line, get squished onto the origin.
This set of vectors (or planes in higher dimensions) that transform to the origin, to 0, are called the Null Space or Kernel of the matrix.
ImportantNull Space
In a system of linear equations, the Null Space of the matrix \(A\) gives all possible solutions to the system when \(A\vec{x} = \vec{0}\)
A.14 Change of Bases
In Section A.11.2.4, we discussed that there many possible basis vectors for a vector space.
The choice of basis vectors determines how to describe other vectors in terms of the origin, the direction of movement and the unit of distance.
As an example, \(\hat{i}\) and \(\hat{j}\) mean we interpret a vector \(\begin{bmatrix}3\\2\end{bmatrix}\) as saying the head of the vector can be found by moving three units horizontally to the right and two units vertically up from the origin.
This relationship between the numbers and a geographic interpretation as a vector is defined by the Coordinate System.
- \(\hat{i}\) and \(\hat{j}\) are part of a “standard” Coordinate system with length one and horizontal and vertical basis vectors of length 1.
A.14.1 Differing Linear Coordinate Systems
Suppose someone else uses a different set of basis vectors, \(\vec{b}_1\) and \(\vec{b}_2\) where from the perspective of the standard coordinate system, \(\vec{b}_1\) points up to the right at a slight angle, and \(\vec{b}_2\) points up to the left at a slight angle.
What the standard system defines as \(\begin{bmatrix}3\\2\end{bmatrix}\) would be described as \(\begin{bmatrix}5/3\\1/3\end{bmatrix}\) in the system with basis vectors \(\vec{b}_1\) and \(\vec{b}_2\).
Important
The original vector has not moved - it is just being described from the perspective of a different coordinate system.
- The origin is the same \(\vec{0}\)
- It is the same approach of scaling each basis vector and adding the results.
- However the orientation of the axes and the scaling of the units is different.
- The choice of these is arbitrary and can be changed to provide a more visually or mathematically convenient perspective of a vector.
- Consider a picture taken by a tilted camera and tilting your head a few degrees so it looks like a normal portrait or landscape perspective. The location of objects and the relationships among objects in the picture did not change, but it might be easier to interpret now that your are looking at it from a new perspective.
In this example, the standard coordinate system would describe \(\vec{b}_1 = \begin{bmatrix}2\\1\end{bmatrix}\) and \(\vec{b}_2 = \begin{bmatrix}-1\\1\end{bmatrix}\)
In the alternate system, \(\vec{b}_1 = \begin{bmatrix}1\\0\end{bmatrix}\) and \(\vec{b}_2 = \begin{bmatrix}0\\1\end{bmatrix}\) and are the unit basis vectors.
A.14.2 Translating (Transforming) a Vector Between Coordinate Systems
Given two coordinate systems we can translate a vector from one representation to the other if we can describe the basis vectors in one system in terms of the other.
Assume there is a vector identified as \(\begin{bmatrix}-1\\2\end{bmatrix}\) in the alternate system.
What would its description be in the standard coordinate system?
We know how to describe the basis vectors in the alternate system using standard coordinates so we can apply the scale from the alternate system to those.
\[-1 \begin{bmatrix}2\\1\end{bmatrix} + 2 \begin{bmatrix}-1\\\,\,\,\,1\end{bmatrix} =\begin{bmatrix}-4\\\,\,\,\,1\end{bmatrix}\]
This is just the same as using the basis vectors of the alternate system, as a transformation matrix to describe the change using the standard coordinate system.
Important
This matrix is called the Change of Basis matrix as it changes \(\hat{i}\) and \(\hat{j}\) to \(\vec{b}_1\) and \(\vec{b}_2\).
That is equivalent to changing the description of the vector based on scaling the basis vectors \(\vec{b}_1\) and \(\vec{b}_2\) to a description using the basis vectors \(\hat{i}\) and \(\hat{j}\) using the standard coordinate system.
- The change of basis matrix allows us to describe a vector from the alternate system in terms of the standard coordinate system basis vectors \(\hat{i}\) and \(\hat{j}\).
\[\begin{bmatrix}2\quad -1\\1\quad\quad 1\end{bmatrix} \begin{bmatrix}-1\\\,\,\,\,2\end{bmatrix} = \begin{bmatrix}-4\\\,\,\,\,1\end{bmatrix}\]
To transform from the standard to the alternate just requires using the inverse of the change of basis matrix.
- To translate a standard coordinate vector \(\begin{bmatrix}3\\2\end{bmatrix}\), multiply it by the inverse of the change of basis matrix to get the description in terms of scaling the basis vectors \(\vec{b}_1\) and \(\vec{b}_2\).
- We get the result mentioned earlier.
\[\begin{bmatrix}2\quad -1\\1\quad\quad 1\end{bmatrix}^{-1} = \begin{bmatrix}\quad 1/3\quad 1/3\\-1/3\quad 2/3\end{bmatrix} \quad \rightarrow\quad \begin{bmatrix}\quad 1/3\quad 1/3\\-1/3\quad 2/3\end{bmatrix}\begin{bmatrix}3\\2\end{bmatrix} = \begin{bmatrix}5/3\\1/3\end{bmatrix}\]
A.14.3 Translating (Transforming) a Matrix Between Coordinate Systems
We can also translate a matrix that describes a transformation for a vector written in one coordinate system so the translated matrix describes the same spatial transformation from the perspective of the basis vectors in the alternate coordinate system.
- This means we can’t just multiply by the coordinate transformation matrix as that would still be describing the transformation in terms of \(\hat{i}\) and \(\hat{j}\).
Assume we have a transformation matrix \(\begin{bmatrix}\quad 0\quad -1\\-1\quad\quad0\end{bmatrix}\) to rotate a vector \(90^\circ\) to the left (counterclockwise) in the standard coordinate system. We want to apply that transformation to a vector in an alternate coordinate system where we know the change of basis matrix is \(\begin{bmatrix}2\quad -1\\1\quad \quad 1\end{bmatrix}\).
The following steps will translate a transformation matrix written in one system so it can describe the same transformation of a vector in an alternate coordinate system by using the change of basis matrix.
- Start with the vector written in the alternate coordinate system.
- Translate it to the standard coordinate system using the change of basis matrix.
- Transform it with the transformation matrix in the standard coordinate system.
- Translate it back to the alternate system using the inverse of the change of basis matrix.
\[\overbrace{\begin{bmatrix}2\quad -1\\1\quad\quad 1\end{bmatrix}^{-1}}^\text{4. Translate to Alternate}\quad \overbrace{\begin{bmatrix}\quad 0\quad -1\\-1\quad\quad0\end{bmatrix}}^{\text{3. Transform in Standard}}\quad\overbrace{\begin{bmatrix}2\quad -1\\1\quad \quad 1\end{bmatrix}}^\text{2. Translate to Standard (CofB)}\overbrace{\vec{v}}^{\text{1. Alternate Basis}} = \overbrace{\begin{bmatrix}1/3\quad -2/3\\5/3\quad\quad -1/3\end{bmatrix}}^\text{ Transform in Alternate}\]
The result of this series of matrix multiplications in the new matrix on the right which will now create the equivalent rotation of \(90^\circ\) left to any vector in the alternate coordinate system based in terms of scaling/shrinking the basis vectors \(\vec{b}_1\) and \(\vec{b}_2\).
Important
We can now choose to use different coordinate systems, and each system’s set of basis vectors’ and go back and forth in a way that makes it easier to do our analysis.
- This can be thought of as similar to using a log transform to minimize numerical precision errors when multiplying a very large number and and very small small number on a computer.
- We take the log of each number, add the logged values, and then use the anti-log (or exponentiation) to translate back to the original space to get the final result.
A.15 Eigenvectors and Eigenvalues of a Linear Transformation Matrix
A.15.1 Background
Eigenvectors and their associated eigenvalues have been used in mathematics to “simplify” the analysis of linear transformations since the 18th century.
- Euler was using linear transformations in \(\mathbb{R}^3\) to analyze the rotation of solid bodies centered on the origin.
- He found that the linear transformation matrix describing the rotation also rotated most vectors.
- However, the vector of the axis of rotation was special in that it did not rotate under the transformation.
- Another way of saying this is the axis of rotation vector remains on its own span after the transformation and is not rotated off of it like most vectors.
- Others studied these special vectors and determined that many (but not all) matrices of linear transformations may have one or more of these special vectors, which remain on their original span, and which may be scaled by the transformation but not rotated off the span.
- In 1904, David Hilbert coined the term eigenvector (German for “own”) as each transformation matrix may have one or more of its “own” special vectors.
- The eigenvalues are the scale factors associated with one more eigenvectors for a matrix.
Important
When a matrix has a set of eigenvectors that span the space, changing the coordinate system to use them as the basis vectors (an eigenbasis), greatly simplifies the transformation matrix.
- Translating the transformation matrix into the eigenbasis coordinate system translates the original matrix into a diagonal matrix.
- The columns now represent each eigenvector.
- The values on the diagonals are the eigenvalues (scale factors) for each eigenvector!
A.15.2 Example
Let’s assume we have a transformation matrix \(\begin{bmatrix}3\quad 1\\0\quad 2\end{bmatrix}\).
We can see from the matrix that \(\hat{i}\) is special in that it is not rotated off of its span (the \(x\) axis). It is only scaled by a factor of 3.
Any other vector on the \(x\) axis is also scaled by a factor of 3.
Thus \(\hat{i}\) is an eigenvector with eigenvalue 3.
It turns out the vector \(\begin{bmatrix}-1 \\\,\,\,\, 2\end{bmatrix}\) is also not rotated off its span and is scaled by a factor of 2.
An other vector in its span is also not rotated off the span and is just scaled by a factor of 2.
Thus \(\begin{bmatrix}-1 \\\,\,\,\, 2\end{bmatrix}\) is an eigenvector with eigenvalue 2.
Important
Using eigenvectors as the basis provides a way of describing a linear transformation that emphasizes the effects of the transformation without worrying about which coordinate system is being used to describe it.
A.15.3 Derivation
Given a transformation matrix \(A\), the definition of an eigenvector \(\vec{v}\) is that the output of \(A\) transforming \(\vec{v}\) is a scaled version of \(\vec{v}\). That can be expressed as:
\[A\vec{v} = \overbrace{\lambda}^\text{eigenvalue}\vec{v} \tag{A.8}\]
To find the eigenvectors and eigenvalues of a matrix \(A\), we have to solve Equation A.8.
We can do some rearranging to put into a matrix form.
\[\begin{align}A\vec{v} &= \lambda\vec{v}\\A\vec{v}&= (\lambda I)\vec{v} \\\rightarrow\\A\vec{v}- (\lambda I)\vec{v}&=\vec{0}\\\rightarrow\\(A- \lambda I)\vec{v}&= \vec{0}\end{align} \tag{A.9}\]
The last line in Equation A.9 says we are looking for a vector\(\vec{v}\) such that the new transformation matrix \((A- \lambda I)\) applied to \(\vec{v}\) maps to \(\vec{0}\).
- This means that we are looking for a vector \(\vec{v}\neq\vec{0}\) that is squished by \((A- \lambda I)\) to \(\vec{0}\).
- That only happens if \(\text{det}(A- \lambda I) = 0\).
Important
We are thus looking for a \(\lambda\) such it causes \((A- \lambda I)\) to be singular with determinant of zero.
As an example, if \(A = \begin{bmatrix}2\quad 2 \\1 \quad 3\end{bmatrix}\) the value of \(\lambda\) that causes \(\text{det}\left(A -\lambda I\right)= \text{det}\left(\begin{bmatrix}2-\lambda \quad\quad 2 \\ \quad1 \quad\quad 3-\lambda\end{bmatrix}\right)= 0\) is \(\lambda = 1\).
- If we had chosen another matrix, the eigenvalue might not be 1.
Since \(\text{det}\left(A -(1)I\right) = 0\) that means there exists a \(\vec{v}\neq\vec{0}\) where \(\left(A -\lambda I\right)\vec{v} = 0\) or \(A\vec{v} =(\lambda)\vec{v}\).
To check if a value of \(\lambda\) is an eigenvalue, you can substitute into \(\text{det}\left(A -\lambda I\right)\) and see if it equals 0.
Using the formula for a 2x2 matrix determinant we can compute \(\text{det}\left(\begin{bmatrix}3-\lambda \quad\quad 1 \\ \quad0 \quad\quad 2-\lambda\end{bmatrix}\right)\) for the original example of \(\begin{bmatrix}3 \quad 1 \\ 0 \quad 2\end{bmatrix}\).
- That gives us the following:
\[\text{det}\left(\begin{bmatrix}3-\lambda \quad\quad 1 \\ \quad0 \quad\quad 2-\lambda\end{bmatrix}\right) = (3 - \lambda)(2-\lambda) - 0(1) = (3 - \lambda)(2-\lambda) = 0.\]
This a quadratic polynomial in \(\lambda\) where the roots of the polynomial are \(3\) and \(2\).
To figure out the eigenvectors with these eigenvalues, substitute the eigenvalue back into the \(\begin{bmatrix}3-\lambda \quad\quad 1 \\ \quad0 \quad\quad 2-\lambda\end{bmatrix}\) and compute the vector.
For eigenvalue 2, we get
\[\begin{align}\begin{bmatrix}3-2 \quad 1 \\ \quad 0 \qquad 2-2\end{bmatrix} \begin{bmatrix}x\\y\end{bmatrix} &= \vec{0}\\\\\begin{bmatrix}1 \quad 1 \\ 0 \quad 0\end{bmatrix} \begin{bmatrix}x\\y\end{bmatrix} &= \vec{0 }\\\rightarrow \\x + y &= 0 \\\rightarrow \\\{x = -1&, y =1\}\end{align}\]
- So an eigenvector for \(\lambda = 2\) is \(\vec{v} = \begin{bmatrix}-1\\1\end{bmatrix}\) and any vector in the span of that line, \(x = -y\), is a solution for the equation.
Similarly, the eigenvector for \(\lambda = 3\) we get
\[\begin{align}\begin{bmatrix}3-3 \quad 1 \\ \quad 0 \qquad 2-3\end{bmatrix} \begin{bmatrix}x\\y\end{bmatrix} &= \vec{0}\\\\\begin{bmatrix}0 \quad\quad 1 \\ 0 \quad -1\end{bmatrix} \begin{bmatrix}x\\y\end{bmatrix} &= \vec{0 }\\\rightarrow \\ y &= 0 \\\rightarrow \\\{x, y =0\}\end{align}\]
- So an eigenvector for \(\lambda = 3\) is \(\vec{v} = \begin{bmatrix}1\\0\end{bmatrix}\) and any vector in the span of that line, \(y=0\), is a solution for the equation.
Note
Note not every matrix has eigenvectors.
A rotation of \(90^\circ\)in \(\mathbb{R}^2\) by definition rotates every vector off of its span.
- The transformation matrix is \(\begin{bmatrix}0 \quad -1 \\ 1 \qquad 0\end{bmatrix}\) and the roots of \(\text{det}(A-\lambda I) = 0\) are the roots of \((-\lambda)(-\lambda) = -1\) so the roots are the complex numbers \(\pm i\).
- Having only complex roots means there are no eigenvectors in \(\mathbb{R}^n\).
For a shear transformation in \(\mathbb{R}^2\), the only eigenvector is \(\hat{i}\) with eigenvalue 1. But \(\hat{i}\) does not generate \(\mathbb{R}^2\) so you can’t have an eigenbasis.
A.15.4 Eigenbases
Assume we have a transformation matrix in \(\mathbb{R}^2\) with two eigenvectors that span the space, say \(\vec{v}_1 = \begin{bmatrix}-1\\0 \end{bmatrix}\) and \(\vec{v}_2 = \begin{bmatrix}0\\2 \end{bmatrix}\).
Putting this into a transformation matrix, we have \(\begin{bmatrix}-1 \quad 0\\\,\,\,\,\,0\quad 2 \end{bmatrix}\) which is a diagonal matrix.
ImportantDiagnonal Matrices and Eigenvectors and Eigenvalues
Any time we have a diagonal matrix, where all off diagonal values = 0, we can interpret this as the matrix of an eigenbasis where each column is an eigenvector with an eigenvalue of the diagonal element for that column.
Diagonal matrices are often easier to work with than non-diagonal matrices.
- As an example, raising a diagonal matrix to the power \(n\) simply requires raising the diagonal values to the power \(n\) and multiplying the vector.
If you have a transformation that has sufficient eigenvectors to create an eigenbasis, you can change to the eigenbasis to make your computations and then change back as desired as seen in Section A.14.3.
Follow similar steps.
- Take the original transformation
- Put the eigenvectors into a change of basis matrix and put that on the right.
- Put the inverse of the eigenvector change of basis matrix on the left.
The resulting matrix is guaranteed to be diagonal which may make the computations easier.
A.15.5 Beyond Matrices
The concepts of eigenvectors and eigenvalues have been looked at from the perspective of matrices which represent linear transformations.
These matrices are functions that map an input vector to an output vector in \(\mathbb{R}^n\).
The concepts of eigenvectors and eigenvalues can be extended to operate in other functions that express linear transformation.