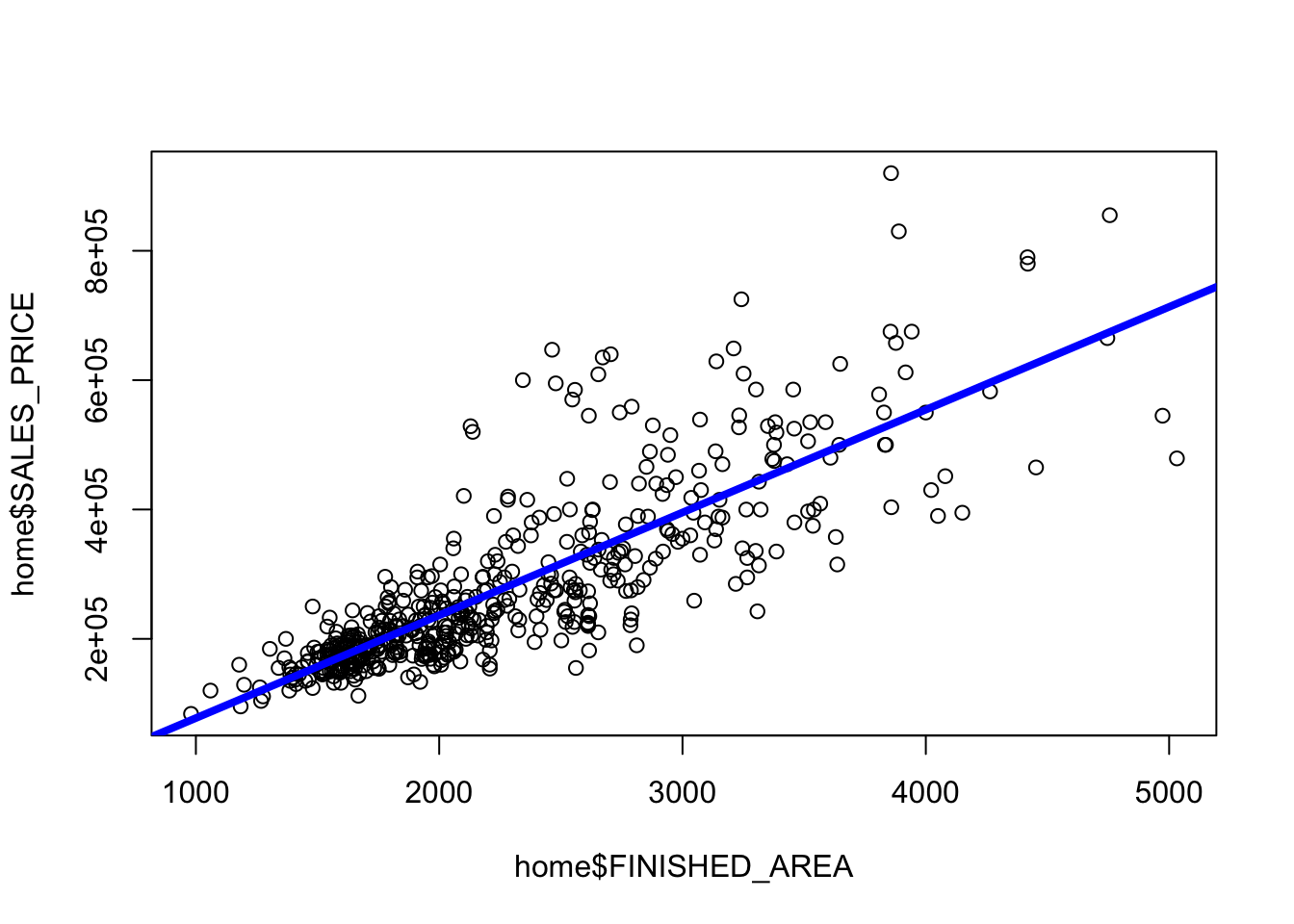
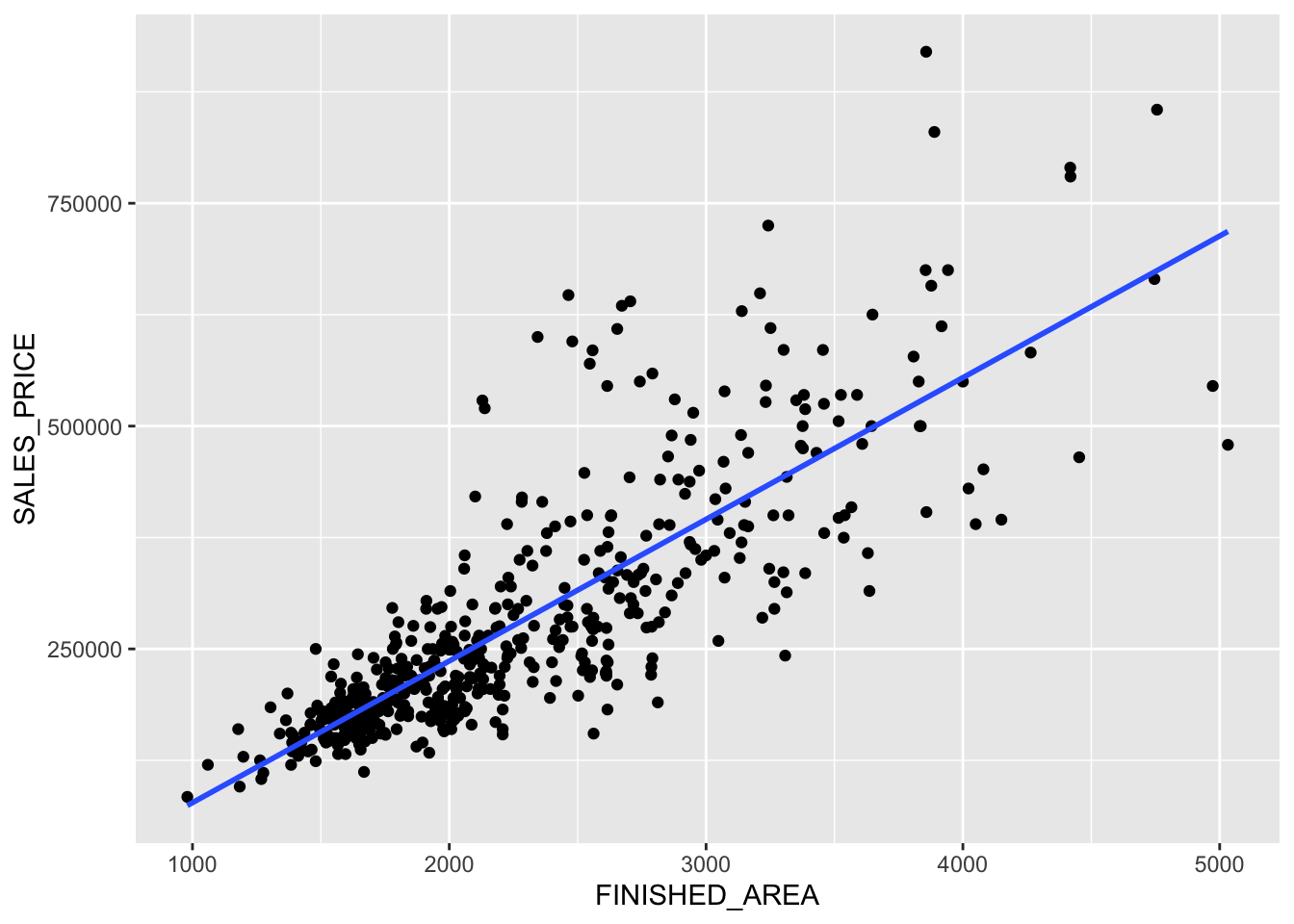
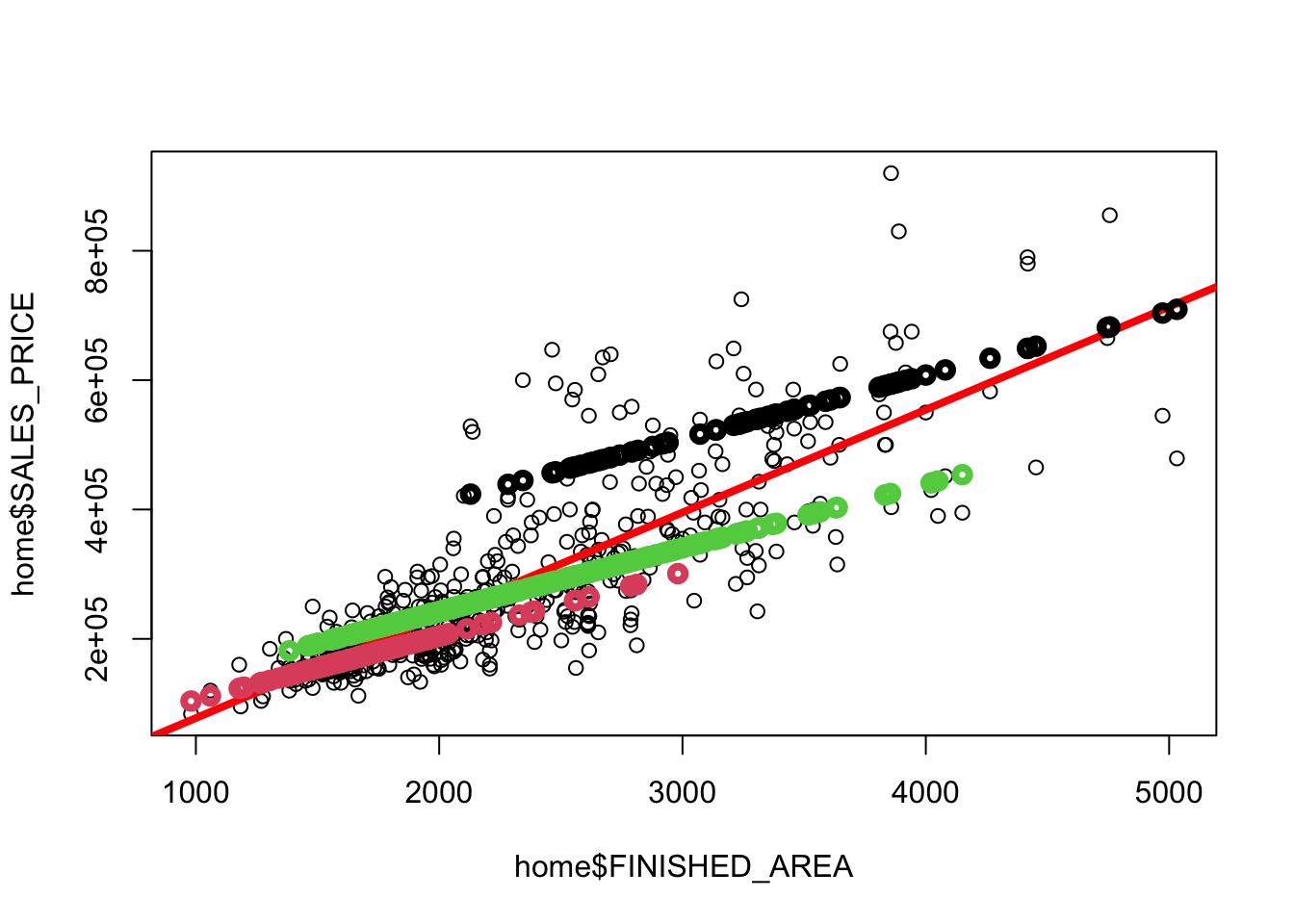
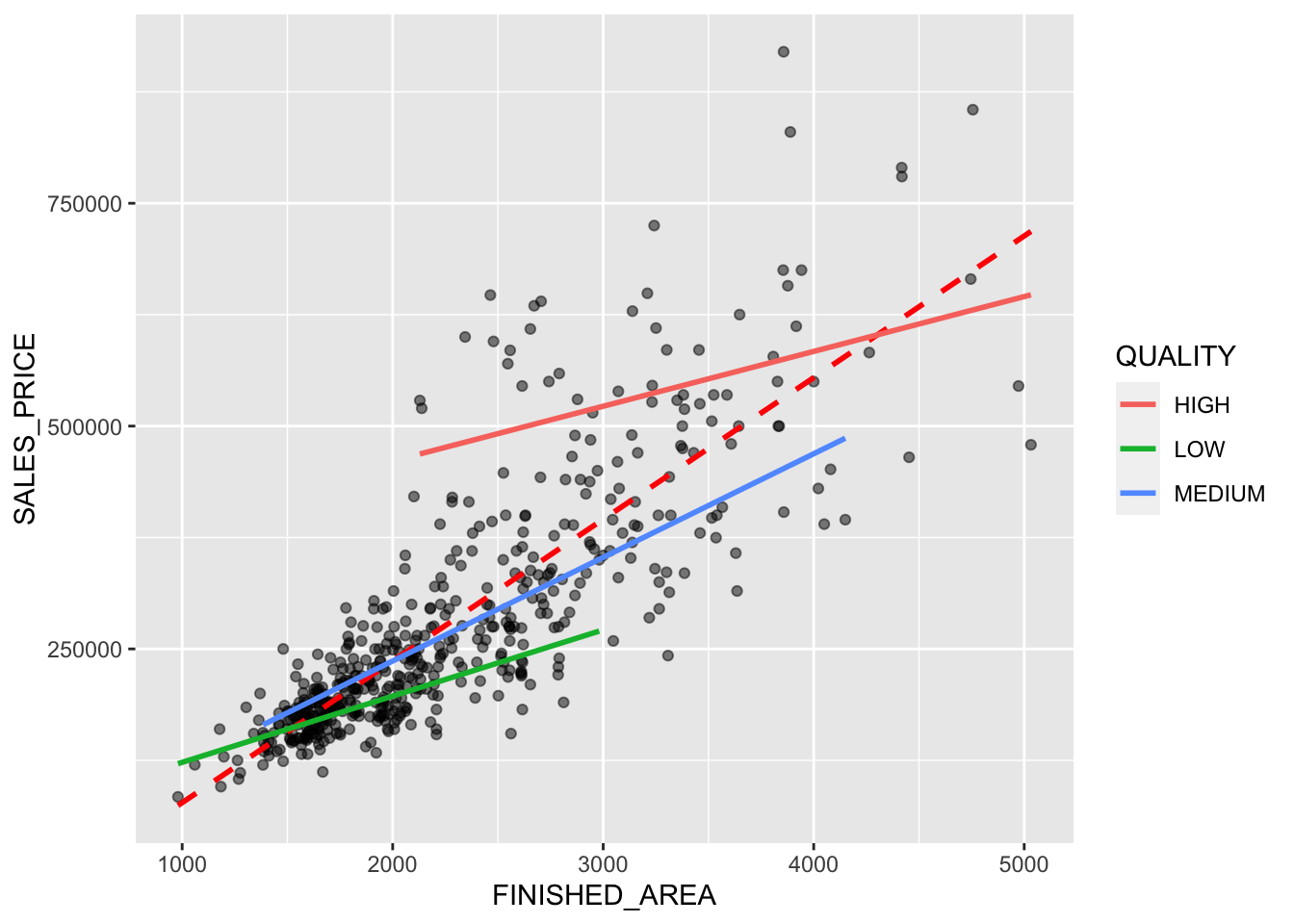
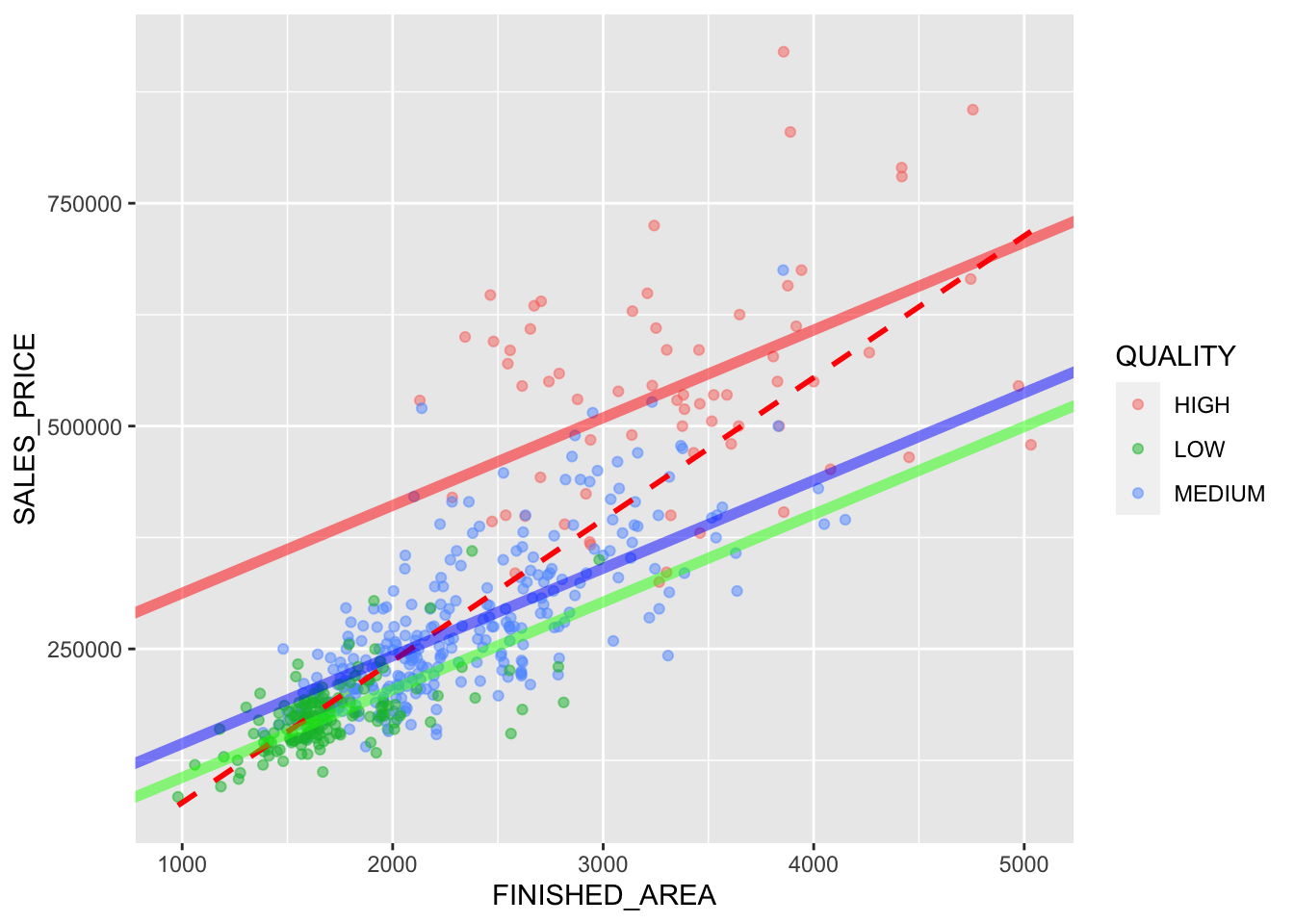
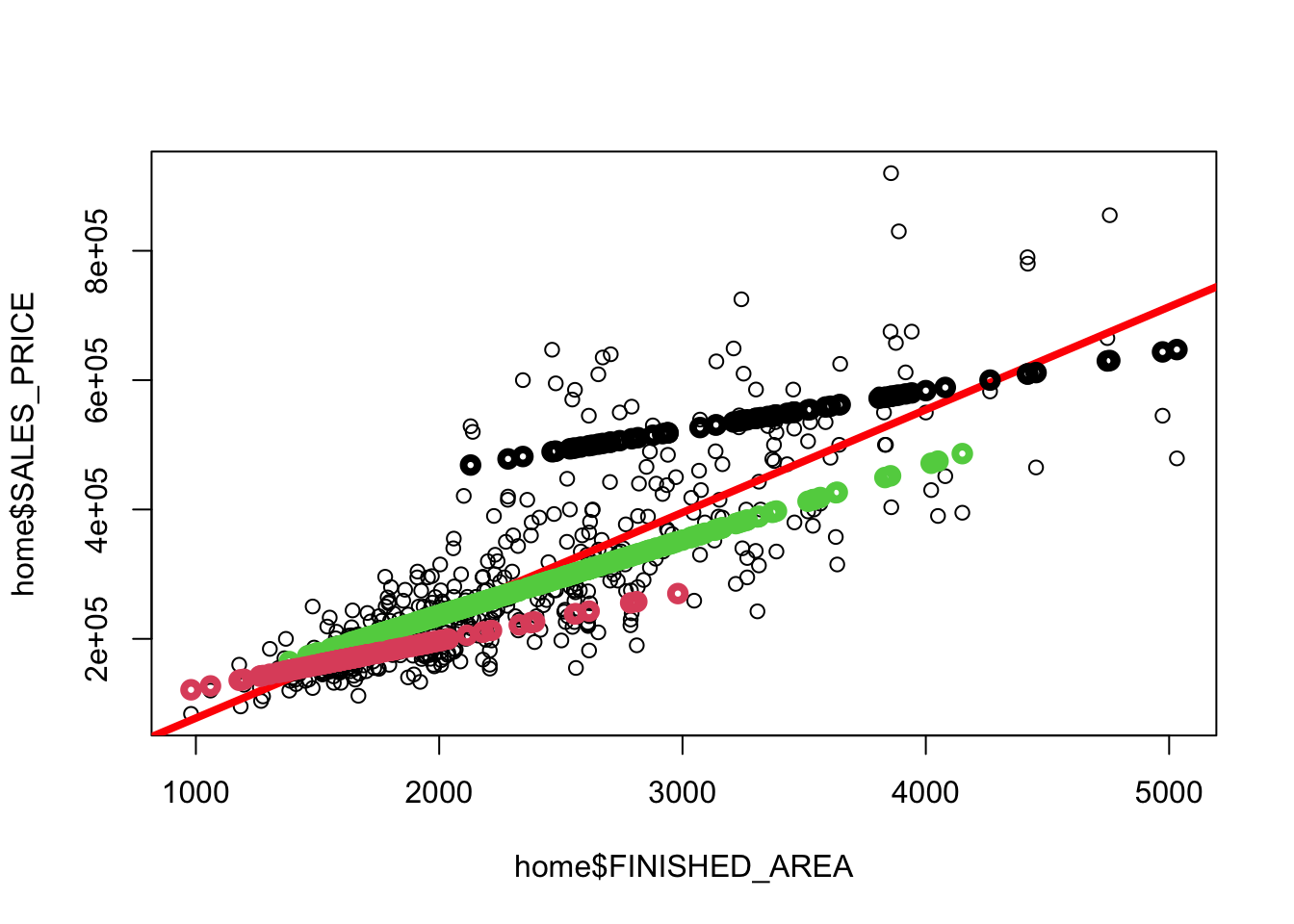
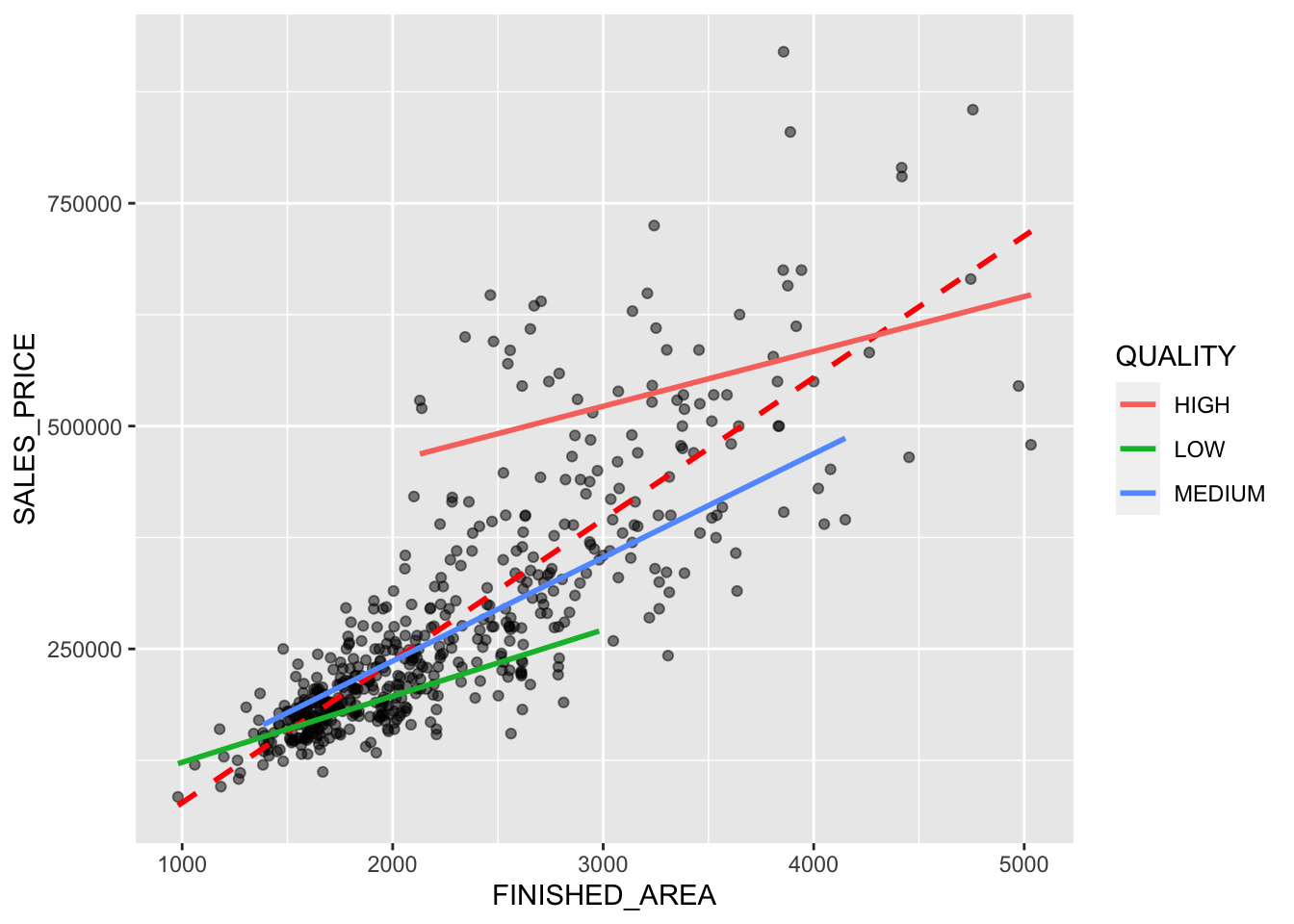
Rows: 522
Columns: 13
$ ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,…
$ SALES_PRICE <dbl> 360000, 340000, 250000, 205500, 275500, 248000, 229900…
$ FINISHED_AREA <dbl> 3032, 2058, 1780, 1638, 2196, 1966, 2216, 1597, 1622, …
$ BEDROOMS <dbl> 4, 4, 4, 4, 4, 4, 3, 2, 3, 3, 7, 3, 5, 5, 3, 5, 2, 3, …
$ BATHROOMS <dbl> 4, 2, 3, 2, 3, 3, 2, 1, 2, 3, 5, 4, 4, 4, 3, 5, 2, 4, …
$ GARAGE_SIZE <dbl> 2, 2, 2, 2, 2, 5, 2, 1, 2, 1, 2, 3, 3, 2, 2, 2, 2, 2, …
$ YEAR_BUILT <dbl> 1972, 1976, 1980, 1963, 1968, 1972, 1972, 1955, 1975, …
$ STYLE <dbl> 1, 1, 1, 1, 7, 1, 7, 1, 1, 1, 7, 1, 7, 5, 1, 6, 1, 7, …
$ LOT_SIZE <dbl> 22221, 22912, 21345, 17342, 21786, 18902, 18639, 22112…
$ AIR_CONDITIONER <chr> "YES", "YES", "YES", "YES", "YES", "YES", "YES", "YES"…
$ POOL <chr> "NO", "NO", "NO", "NO", "NO", "YES", "NO", "NO", "NO",…
$ QUALITY <chr> "MEDIUM", "MEDIUM", "MEDIUM", "MEDIUM", "MEDIUM", "MED…
$ HIGHWAY <chr> "NO", "NO", "NO", "NO", "NO", "NO", "NO", "NO", "NO", …