1 Introduction
1.1 The Data Science Life Cycle
Statistical Machine Learning ideally occurs within the context of a Data Science life cycle focused on solving a problem. There are many possible representations of a Data Science life cycle. I like the one in Figure 1.1 as it starts with the idea that Data Science is about answering a question. Once you answer that question, whatever answer you got may generate another question.
It also illustrates that Data Science is not linear and does not always flow in one direction. As you get into later steps, you may realize you need to back up to an earlier step to generate a better solution.
This course focuses on steps 4 and 5. As you get to the final project, you will need to consider steps 1 through 6.
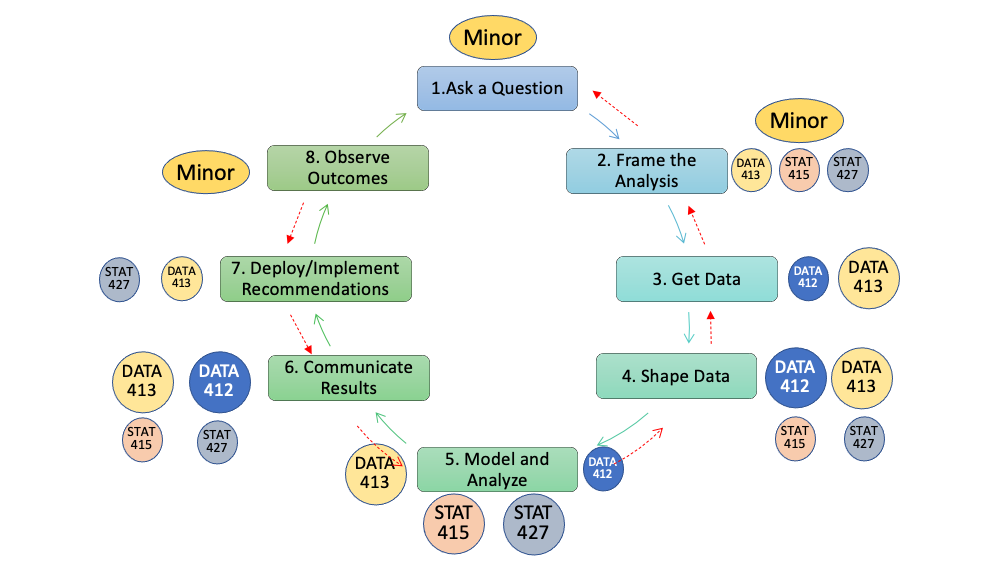
Figure 1.2 puts this course into context of some other AU undergraduate courses with respect to the life cycle. Data 412 teaches how to execute the life cycle with an emphasis on manipulating and visualizing data. DATA 413 teaches how to execute the life cycle for more complex problems with emphasis on acquiring data from multiple sources and then using more sophisticated strategies and methods for interactive analysis and functional programming. STAT 415 focuses on the theory and methods for Linear Regression and its extensions into a General Linear Model. Finally, this course is about building one’s ability to apply multiple analytical methods for answering questions and understanding data. This course is about moving from imposing models on data to letting the data help us understand how best to model the world to achieve our analytical goals.
1.1.1 Statistical Machine Learning
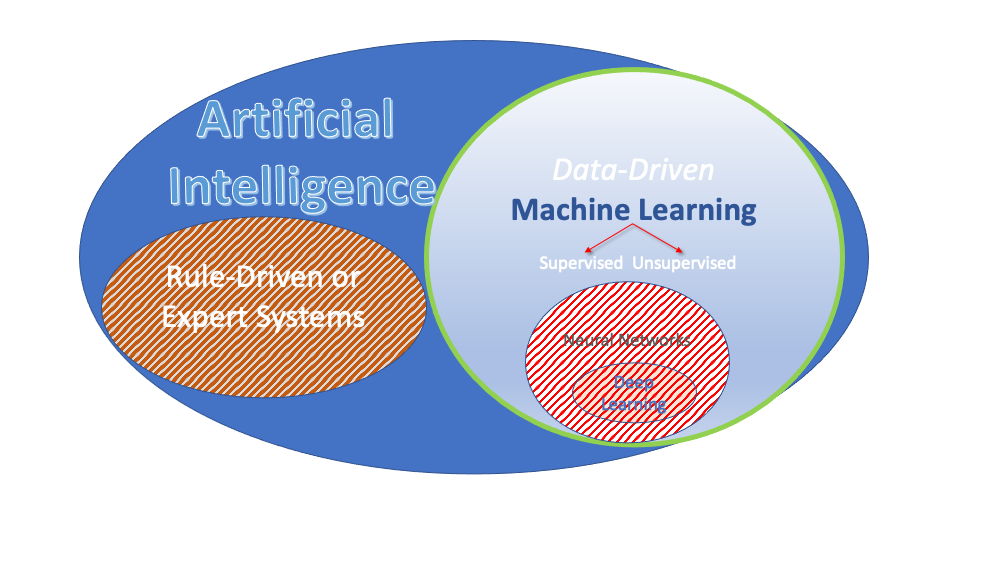
You will hear a lot of terms in discussions about Machine Learning. The Venn Diagram in Figure 1.3 provides some context for our focus in this course. We will be examining supervised and unsupervised methods for statistical machine learning. However, we will likely not have time to delve into neural networks and deep learning.
1.2 Responsible Data Science
Implicit in Figure 1.1 is the idea that at each step the data scientist makes choices that may have implications for responsible data science. As seen in Figure 1.4, responsible data science includes considerations for how to think about the choices one makes at each step as well as the attributes of the analysis.
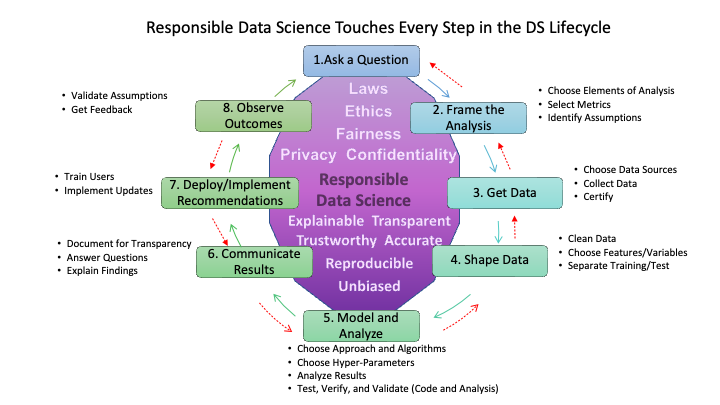
The choice of the original question has ethical implications. Choices at each step in the process can infuse bias against individuals or groups into the eventual results. This is not the same as the statistical use of the word bias (which is about systematic deviations of an estimate from the true value). Here, we are talking about the bias that may stem from historical or current prejudices (often captured in the data) that lead to disparate outcomes for different groups.
Biases may be explicit or implicit, i.e., unknown to the practitioner but still influencing their work. A data scientist should be aware that bias can exist in historical data, in the humans shaping or contributing to the analysis and algorithms, and/or in the interpretation or communications of results. Numbers may not be inherently biased, but they can represent bias in everyday life. Often, when the data has unbalanced representations of the population, it is not a choice of whether the outcomes are biased against a group but how to minimize the bias or unfairness across different groups.
Statistical machine learning is just as prone to human biases as any other analysis method. As we go through the course you will be asked at times to consider the ethical implications made in the choice of questions, the choice of data, the choice of model tuning and how results are communicated. Who are the affected groups and individuals? Is there substantial evidence to support your conclusions?
Machine learning is a collection of powerful methods and algorithms for understanding data. However, the use of machine learning is subject to the choices of humans. We should be aware of the legal and ethical implications of the choices we make when using these powerful tools so we are practicing responsible data science.